HBase集群安装部署
HBase需要依赖于HDFS和Zookeeper服务
在具体安装HBase集群之前,我们需要先确认JDK的版本和Hadoop的版本
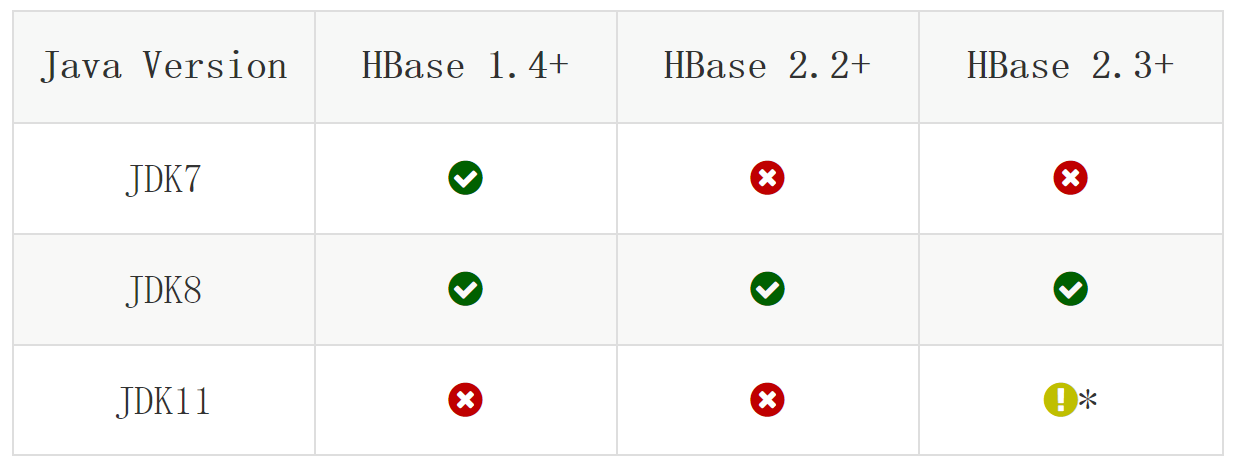
HBase与JDK版本对应关系如下:
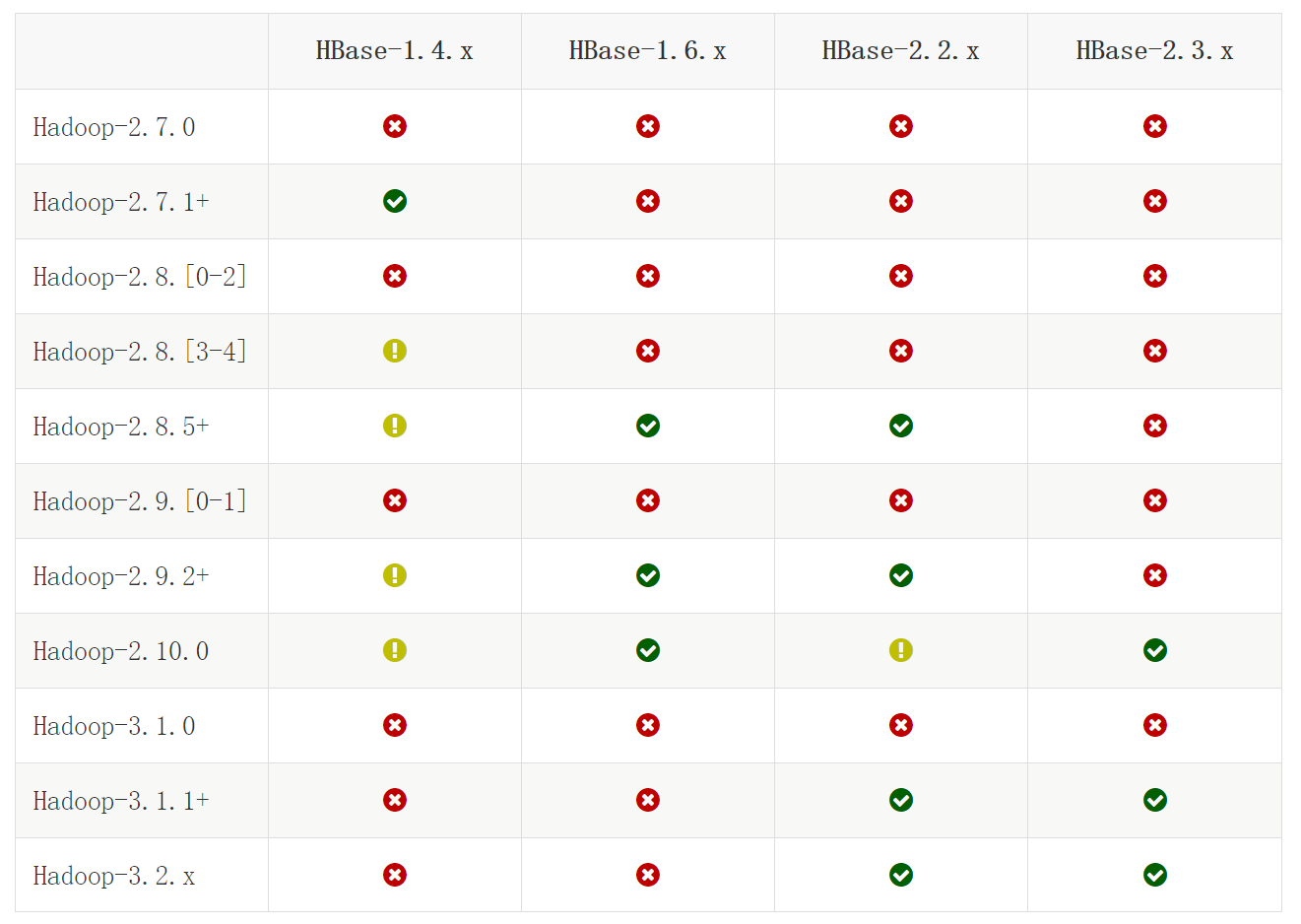
HBase与Hadoop版本对应关系如下:
咱们本套课程中JDK使用的是1.8版本,HBase的所有版本都是支持的。
Hadoop版本我们使用的是3.2.0,由图中内容可知,我们只能选择HBase2.2.x或者HBase-2.3.x
一般不建议选最新的那个版本,所以在这里我们选择HBase2.2.6版本。
HBase所有版本的下载地址:
https://archive.apache.org/dist/hbase/
HBase2.2.6版本的下载地址:
https://archive.apache.org/dist/hbase/2.2.6/hbase-2.2.6-bin.tar.gz
安装包百度网盘链接地址获取方式如下:
注意:为了保证下载链接地址一直可用,在这里通过微信公众号【大数据1024】获取,失效的话可以在公众号中随时动态更新。

扫码关注之后回复hbase即可获取下载地址。
最终下载好的HBase安装包是这个:hbase-2.2.6-bin.tar.gz
HBase支持单机安装和分布式安装,在这里就直接演示分布式安装了。
HBase集群也是支持主节点和从节点的,在这计划使用bigdata01、02、03这三台机器。
建议把HBase的从节点和Hadoop集群的从节点部署在相同的机器上面,可以最大化利用数据本地化特性。
所以最终的节点规划如下:
bigdata01 master(HBase的主节点)
bigdata02 regionserver(HBase的从节点)
bigdata03 regionserver(HBase的从节点)
下面开始安装部署:
bigdata01、02、03这三台机器的基础环境是OK的,并且上面已经运行了一套Hadoop的一主两从的集群。
1:首先在bigdata01上进行操作,将HBase安装包上传到bigdata01的/data/soft目录中
[root@bigdata01 soft]# ll
-rw-r--r--. 1 root root 220469021 Oct 31 2020 hbase-2.2.6-bin.tar.gz
2:解压
[root@bigdata01 soft]# tar -zxvf hbase-2.2.6-bin.tar.gz
3:修改配置文件
首先修改hbase-env.sh,在文件末尾直接添加以下配置即可
[root@bigdata01 soft]# cd hbase-2.2.6/conf
[root@bigdata01 conf]# vi hbase-env.sh
....
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_HOME=/data/soft/hadoop-3.2.0
export HBASE_MANAGES_ZK=false
export HBASE_LOG_DIR=/data/hbase/logs
接下来修改hbase-site.xml
hbase-site.xml中默认有3个配置参数,先修改里面hbase.cluster.distributed和hbase.tmp.dir的值,hbase.unsafe.stream.capability.enforce的值默认为false即可。
[root@bigdata01 conf]# vi hbase-site.xml
<!--是否为分布式模式部署,true表示分布式部署-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 本地文件系统tmp目录-->
<property>
<name>hbase.tmp.dir</name>
<value>/data/hbase/tmp</value>
</property>
<!-- 在分布式情况下, 一定设置为false -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
前面这几个已有的参数修改完毕以后,还需要向hbase-site.xml中添加下面这些参数
[root@bigdata01 conf]# vi hbase-site.xml
.......
<!--设置HBase表数据,也就是HBase数据在hdfs上的存储根目录-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://bigdata01:9000/hbase</value>
</property>
<!--zookeeper集群的URL配置,多个host中间用逗号隔开-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>bigdata01,bigdata02,bigdata03</value>
</property>
<!--HBase在zookeeper上数据的根目录znode节点-->
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
<!--设置zookeeper通信端口,不配置也可以,zookeeper默认就是2181-->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
最后修改regionservers文件,在里面添加hbase从节点的主机名或者ip
[root@bigdata01 conf]# vi regionservers
bigdata02
bigdata03
4:将bigdata01中修改完配置的HBase目录远程拷贝到bigdata02和bigdata03上
[root@bigdata01 soft]# scp -rq hbase-2.2.6 bigdata02:/data/soft/
[root@bigdata01 soft]# scp -rq hbase-2.2.6 bigdata03:/data/soft/
5:启动HBase集群
注意:在启动HBase集群之前一定要确保Hadoop集群和Zookeeper集群已经正常启动了。
先启动Hadoop集群
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
再启动Zookeeper集群
[root@bigdata01 apache-zookeeper-3.5.8-bin]# bin/zkServer.sh start
[root@bigdata02 apache-zookeeper-3.5.8-bin]# bin/zkServer.sh start
[root@bigdata03 apache-zookeeper-3.5.8-bin]# bin/zkServer.sh start
最后在bigdata01上启动HBase集群
[root@bigdata01 hbase-2.2.6]# bin/start-hbase.sh
6:验证集群
在bigdata01上执行jps命令,会发现多了一个HMaster进程,这个就是HBase集群主节点中的进程
[root@bigdata01 hbase-2.2.6]# jps
3826 NameNode
5528 QuorumPeerMain
5736 HMaster
4093 SecondaryNameNode
4334 ResourceManager
然后在bigdata02上执行jps命令,会发现多了一个HRegionServer进程,这个就是HBase集群从节点中的进程
[root@bigdata02 ~]# jps
2631 QuorumPeerMain
2249 NodeManager
2139 DataNode
2715 HRegionServer
然后在bigdata03上执行jps命令,会发现多了一个HRegionServer进程,这个就是HBase集群从节点中的进程
[root@bigdata03 ~]# jps
2625 QuorumPeerMain
2250 NodeManager
2140 DataNode
2702 HRegionServer
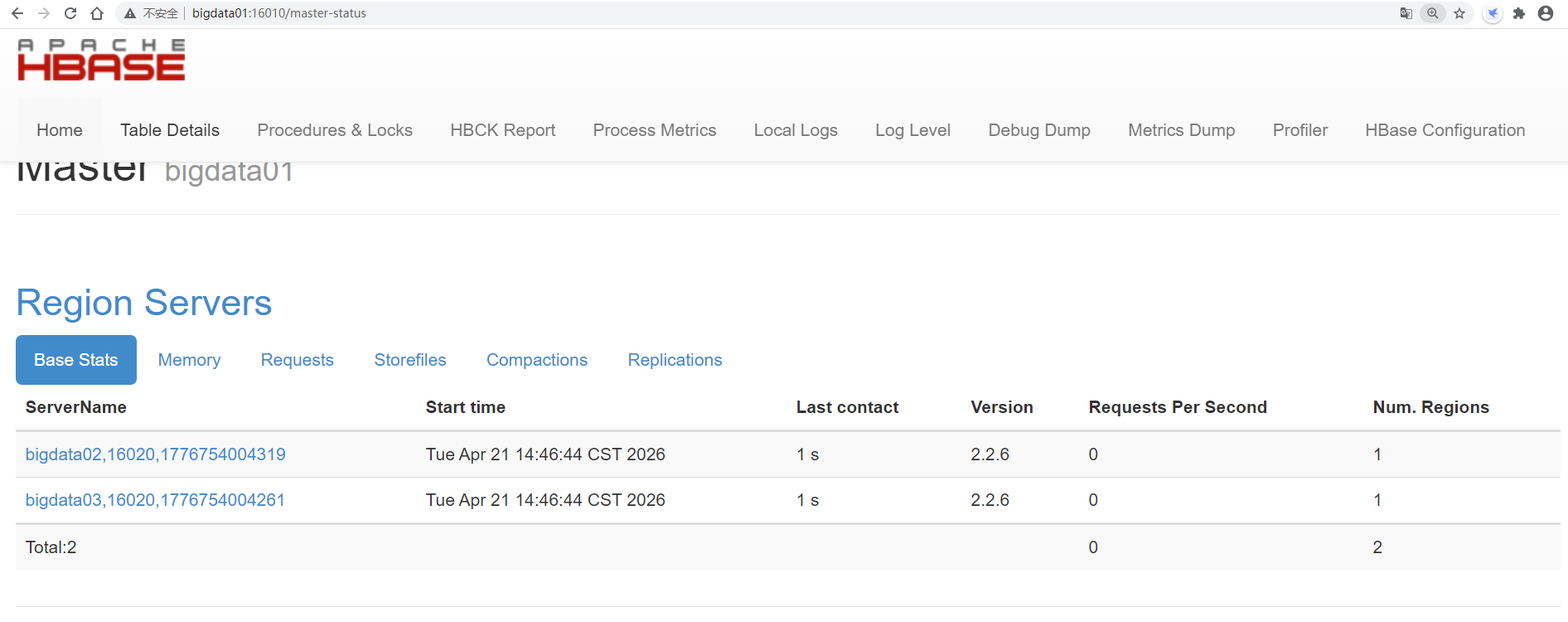
如果发现HMaster进程和HRegionServer进程都在,说明HBase进程正常启动了
HBase提供的有web界面,可以通过浏览器确认集群是否正常启动,端口默认是16010
7:停止HBase集群
注意:在停止集群进程的时候,要先停HBase集群进程,再停止Zookeeper集群进程,否则HBase停止程序会一直卡住不动。
[root@bigdata01 hbase-2.2.6]# bin/stop-hbase.sh