Hadoop之HDFS详解
前面我们把hadoop集群安装好了,下面我们就开始正式进入到Hadoop的学习,咱们前面说过,Hadoop中其实有三大组件,HDFS、MapReduce、YARN 现在我们先来学习一下HDFS这个组件
目录
- HDFS介绍
- HDFS(Hadoop Distributed File System)
- HDFS的Shell介绍
- HDFS的常见Shell操作
- HDFS案例实操
- Java代码操作HDFS
- HDFS体系结构
- HDFS的回收站
- HDFS的安全模式
HDFS介绍
我们前面已经知道了HDFS是一个分布式的文件系统,具体这个分布式文件系统是如何实现的呢?
我们来举个例子分析一下。
小明租房:
小明同学呢,今年是大四,需要离校去实习了,出去实习首要解决的是住宿的问题,目前软件行业很少包住宿的,反正我是没听说过,但是小明呢,有一个特点,就是懒,还穷,天天出去住酒店肯定是住不起的,那只能租房了,租房呢他还不想自己去找房子,嫌麻烦,所以就随便在路边找了一个二房东贴的广告,单间出租,拎包入住,无中介费,押一付一,一月300,小明一看,可以,还不错,所以就直接打电话过去看房子办手续了,这样就解决了住宿的问题。
紧接着小明的同学看他这么快就搞定了住宿问题,房租也挺便宜,都问他要二房东的电话,小明就把二房东的电话发到了他们的年级群里,上千人啊,结果二房东的手机就被打爆了,最后只能关机了,人太多了,实在搞不定了。
因为目前有租房需求的学员太多了,全部都去找这一个二房东,他是搞不定的,因为他每天带看的人数是有限的。
那这个时候怎么办呢?
小明同学还是比较热心的,发现二房东解决不了这么大的需求,然后他正发愁呢,结果一抬头看到了一个中介公司,小明露出了满嘴的大白牙。
然后他就顺利搞到了这个中介公司的电话,赶紧把这个电话发到了年级群里面,这个时候,当再有学员有租房需求的时候,直接打中介公司的电话,然后中介公司会让具体的工作人员直接联系这个学员,负责他的租房需求,每一个工作人员最多负责5个人,因为中介公司里面是有很多工作人员的,这样一分流,就很轻松的解决了这个问题。
这个时候针对中介公司而言,它只负责管理房源和工作人员就行了,具体干活的是工作人员。
这样就算同时过来很多人,中介公司也是可以扛得住的,因为具体看房租房的流程是直接和工作人员对接的,不会造成阻塞。
ok 这就是小明租房的一个案例,那这个案例和我们要讲的HDFS有什么关系呢?
不要着急,我们来往下面看。
假设让我们来设计一个分布式的文件系统,我们该如何设计呢?
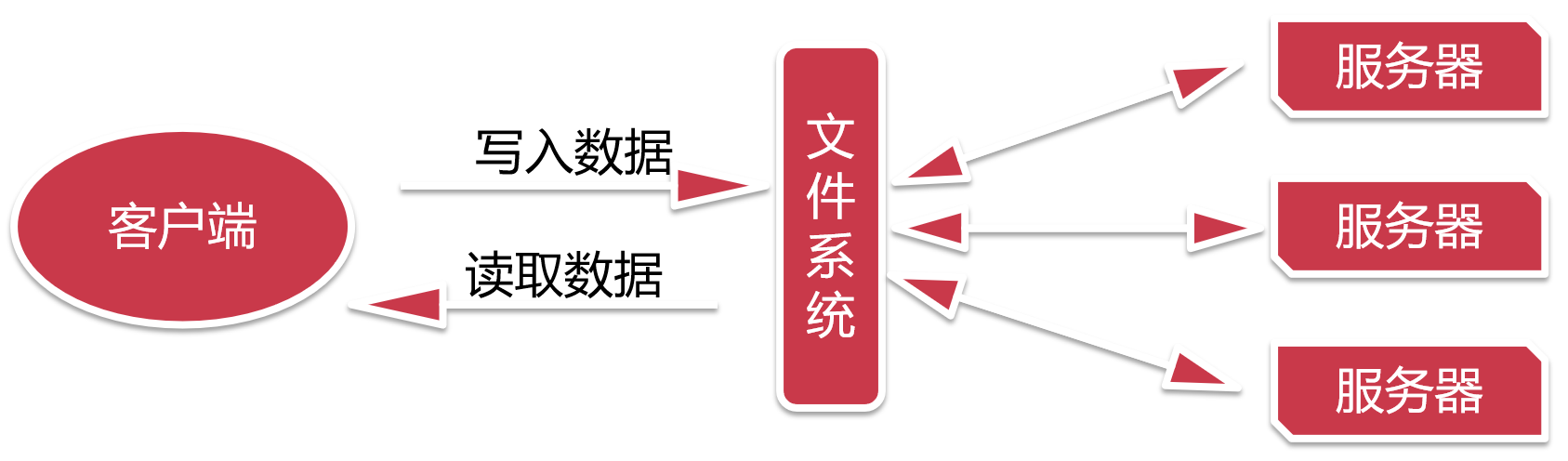
看这个图片,用户在写入数据和读取数据的时候会通过一个文件系统,这个文件系统后面会有很多台服务器,所以我们的数据就可以存储在多台服务器上面。后期服务器增加或者减少,对我们用户而言,不用关注,这个统一由文件系统进行管理,我们只需要和文件系统进行交互就可以了。
这样是不是就实现了分布式存储了,这种方案在实际应用中可行吗?
在这里就可以把文件系统理解为二房东,服务器理解为房子,这种设计架构会存在一个问题,假设同时过来很多人都需要租房子,那么一个二房东是忙不过来的,就会造成阻塞。
那继续往下面看
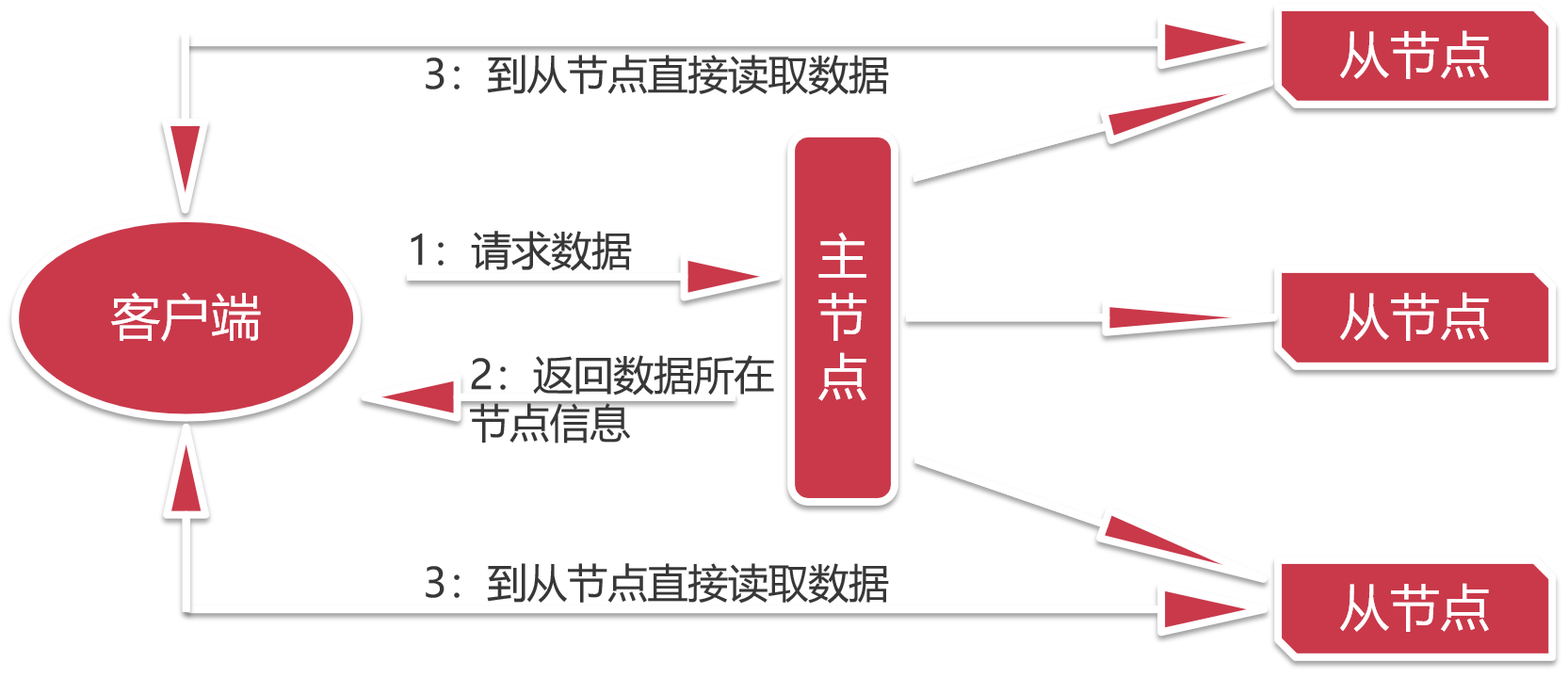
现在这种设计是,我们去找一个中介公司,这里的主节点就可以理解为一个中介公司
这里的从节点就可以理解为是房源,中介公司会在每块房源都安排一个工作人员,当我们找房子的时候,先联系中介公司,中介公司会告诉我们哪里有房子,并且把对应工作人员的信息告诉我们,我们就可以直接去找对应的工作人员去租房子。这样对于中介公司而言,就没什么压力了。
中介公司只负责管理房源和工作人员信息,具体干活的是工作人员。
这样就算同时过来很多人,中介公司也是可以扛得住的,因为具体看房租房的流程是我们直接和工作人员联系的,不会造成阻塞。
所以对应到我们的分布式存储设计上面:
用户请求查看数据时候会请求主节点,主节点上面会维护所有数据的存储信息,
主节点会把对应数据所在的节点信息返回给用户,
然后用户根据数据所在的节点信息去对应的节点去读取数据,这样压力就不会全部在主节点上面。
这个就是HDFS这个分布式文件系统的设计思想。
HDFS(Hadoop Distributed File System)
HDFS的全称是Hadoop Distributed File System ,Hadoop的 分布式 文件 系统
它是一种允许文件通过网络在多台主机上分享的文件系统,可以让多台机器上的多个用户分享文件和存储空间
其实分布式文件管理系统有很多,HDFS只是其中一种实现而已
还有 GFS(谷歌的)、TFS(淘宝的)、S3(亚马逊的)
为什么会有多种分布式文件系统呢?这样不是重复造轮子吗?
不是的,因为不同的分布式文件系统的特点是不一样的,HDFS是一种适合大文件存储的分布式文件系统,不适合小文件存储,什么叫小文件,例如,几KB,几M的文件都可以认为是小文件
HDFS的Shell介绍
通过前面的学习,我们对HDFS有了基本的了解,下面我们就想实际操作一下,来通过实操加深对HDFS的理解
针对HDFS,我们可以在shell命令行下进行操作,就类似于我们操作linux中的文件系统一样,但是具体命令的操作格式是有一些区别的
格式如下:
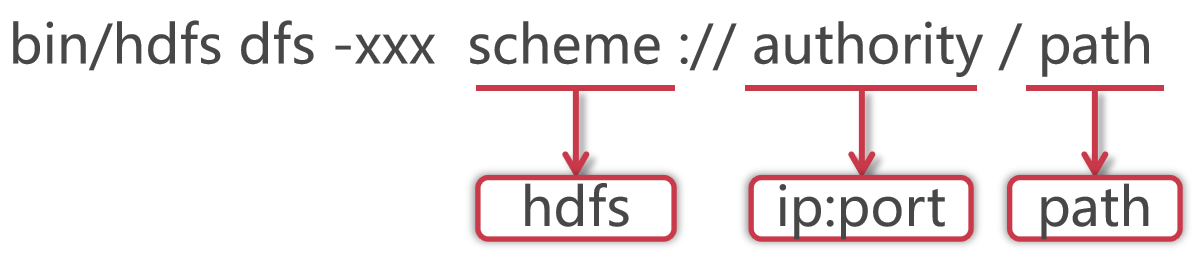
使用hadoop bin目录的hdfs命令,后面指定dfs,表示是操作分布式文件系统的,这些属于固定格式。
如果在PATH中配置了hadoop的bin目录,那么这里可以直接使用hdfs就可以了
这里的xxx是一个占位符,具体我们想对hdfs做什么操作,就可以在这里指定对应的命令了
大多数hdfs 的命令和对应的Linux命令类似
HDFS的schema是hdfs,authority是集群中namenode所在节点的ip和对应的端口号,把ip换成主机名也是一样的,path是我们要操作的文件路径信息
其实后面这一长串内容就是core-site.xml配置文件中fs.defaultFS属性的值,这个代表的是HDFS的地址。
HDFS的常见Shell操作
下面我们就来学习一下HDFS中的一些常见的shell操作
其实hdfs后面支持很多的参数,但是有很多是很少用的,在这里我们把一些常用的带着大家一块学习一下,如果大家后期有一些特殊的需求,可以试着来看一下hdfs的帮助文档
直接在命令行中输入hdfs dfs,可以查看dfs后面可以跟的所有参数
注意:这里面的[]表示是可选项,<>表示是必填项
[root@bigdata01 hadoop-3.2.0]# hdfs dfs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touch [-a] [-m] [-t TIMESTAMP ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command [genericOptions] [commandOptions]
- -ls:查询指定路径信息
首先看第一个ls命令
查看hdfs根目录下的内容,什么都不显示,因为默认情况下hdfs中什么都没有
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls hdfs://bigdata01:9000/
[root@bigdata01 hadoop-3.2.0]#
其实后面hdfs的url这一串内容在使用时默认是可以省略的,因为hdfs在执行的时候会根据HDOOP_HOME自动识别配置文件中的fs.defaultFS属性
所以这样简写也是可以的
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
[root@bigdata01 hadoop-3.2.0]#
- -put:从本地上传文件
接下来我们向hdfs中上传一个文件,使用Hadoop中的README.txt,直接上传到hdfs的根目录即可
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -put README.txt /
上传成功之后没有任何提示,注意,没有提示就是最好的结果
确认一下刚才上传的文件
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
Found 1 items
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:34 /README.txt
在这里可以发现使用hdfs中的ls查询出来的信息和在linux中执行ll查询出来的信息是类似的
在这里能看到这个文件就说明刚才的上传操作是成功的
- -cat:查看HDFS文件内容
文件上传上去以后,我们还想查看一下HDFS中文件的内容,很简单,使用cat即可
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -cat /README.txt
For the latest information about Hadoop, please visit our website at:
http://hadoop.apache.org/
and our wiki, at:
http://wiki.apache.org/hadoop/
...........
- -get:下载文件到本地
如果我们想把hdfs中的文件下载到本地linux文件系统中需要怎么做呢?使用get即可实现
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -get /README.txt .
get: `README.txt': File exists
注意:这样执行报错了,提示文件已存在,我这条命令的意思是要把HDFS中的README.txt下载当前目录中,但是当前目录中已经有这个文件了,要么换到其它目录,要么给文件重命名
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -get /README.txt README.txt.bak
[root@bigdata01 hadoop-3.2.0]# ll
total 188
drwxr-xr-x. 2 1001 1002 203 Jan 8 2019 bin
drwxr-xr-x. 3 1001 1002 20 Jan 8 2019 etc
drwxr-xr-x. 2 1001 1002 106 Jan 8 2019 include
drwxr-xr-x. 3 1001 1002 20 Jan 8 2019 lib
drwxr-xr-x. 4 1001 1002 4096 Jan 8 2019 libexec
-rw-rw-r--. 1 1001 1002 150569 Oct 19 2018 LICENSE.txt
-rw-rw-r--. 1 1001 1002 22125 Oct 19 2018 NOTICE.txt
-rw-rw-r--. 1 1001 1002 1361 Oct 19 2018 README.txt
-rw-r--r--. 1 root root 1361 Apr 8 15:41 README.txt.bak
drwxr-xr-x. 3 1001 1002 4096 Apr 7 22:08 sbin
drwxr-xr-x. 4 1001 1002 31 Jan 8 2019 share
- -mkdir [-p]:创建文件夹
后期我们需要在hdfs中维护很多文件,所以就需要创建文件夹来进行分类管理了
下面我们来创建一个文件夹,hdfs中使用mkdir命令
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -mkdir /test
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
Found 2 items
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:34 /README.txt
drwxr-xr-x - root supergroup 0 2020-04-08 15:43 /test
如果要递归创建多级目录,还需要再指定-p参数
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -mkdir -p /abc/xyz
You have new mail in /var/spool/mail/root
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
Found 3 items
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:34 /README.txt
drwxr-xr-x - root supergroup 0 2020-04-08 15:44 /abc
drwxr-xr-x - root supergroup 0 2020-04-08 15:43 /test
想要递归显示所有目录的信息,可以在ls后面添加-R参数
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls -R /
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:34 /README.txt
drwxr-xr-x - root supergroup 0 2020-04-08 15:44 /abc
drwxr-xr-x - root supergroup 0 2020-04-08 15:44 /abc/xyz
drwxr-xr-x - root supergroup 0 2020-04-08 15:43 /test
- -rm [-r]:删除文件/文件夹
如果想要删除hdfs中的目录或者文件,可以使用rm
删除文件
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm /README.txt
Deleted /README.txt
删除目录,注意,删除目录需要指定-r参数
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm /test
rm: `/test': Is a directory
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r /test
Deleted /test
如果是多级目录,可以递归删除吗?可以
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r /abc
Deleted /abc
HDFS案例实操
需求:统计HDFS中文件的个数和每个文件的大小
我们先向HDFS中上传几个文件,把hadoop目录中的几个txt文件上传上去
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -put LICENSE.txt /
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -put NOTICE.txt /
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -put README.txt /
1:统计根目录下文件的个数
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls / |grep /| wc -l
3
2:统计根目录下每个文件的大小,最终把文件名称和大小打印出来
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls / |grep / | awk '{print $8,$5}'
/LICENSE.txt 150569
/NOTICE.txt 22125
/README.txt 1361
Java代码操作HDFS
前面我们学习了在shell命令行下操作hdfs,shell中操作hdfs是比较常见的操作,但是在工作中也会遇到一些需求是需要通过代码操作hdfs的,下面我们就来看一下如何使用java代码操作hdfs
在具体操作之前需要先明确一下开发环境,代码编辑器使用idea,当然了eclipse也可以
在创建项目的时候我们会创建maven项目,使用maven来管理依赖,是比较方便的。
在这里我会把idea的安装包和maven的安装包发给大家
考虑可能会有同学没有使用过maven,所以在这里大致说一下maven在windows中的安装配置。
在这里我们使用apache-maven-3.0.5-bin.zip ,当然了,其它版本也可以,没有什么本质的区别
把apache-maven-3.0.5-bin.zip解压到某一个目录下面,
在这里我解压到了D:\Program Files (x86)\apache-maven-3.0.5目录
解压之后,建议修改一下maven的配置文件,把maven仓库的地址修改到其它盘,例如D盘,默认是在C盘的用户目录下
修改D:\Program Files (x86)\apache-maven-3.0.5\conf下的settings.xml文件
将localRepository标签从注释中移出来,然后将值该为D:.m2,效果如下:
这里的目录名字可以随意起,只要易于识别就可以
<localRepository>D:\.m2</localRepository>
这样修改之后,maven管理的依赖jar包都会保存到D:.m2目录下了。
接下来需要配置maven的环境变量,和windows中配置JAVA_HOME环境变量是一样的。
先在环境变量中配置M2_HOME=D:\Program Files (x86)\apache-maven-3.0.5
然后在PATH环境变量中添加%M2_HOME%\bin即可
环境变量配置完毕以后,打开cmd窗口,输入mvn命令,只要能正常执行就说明windows本地的maven环境配置好了。
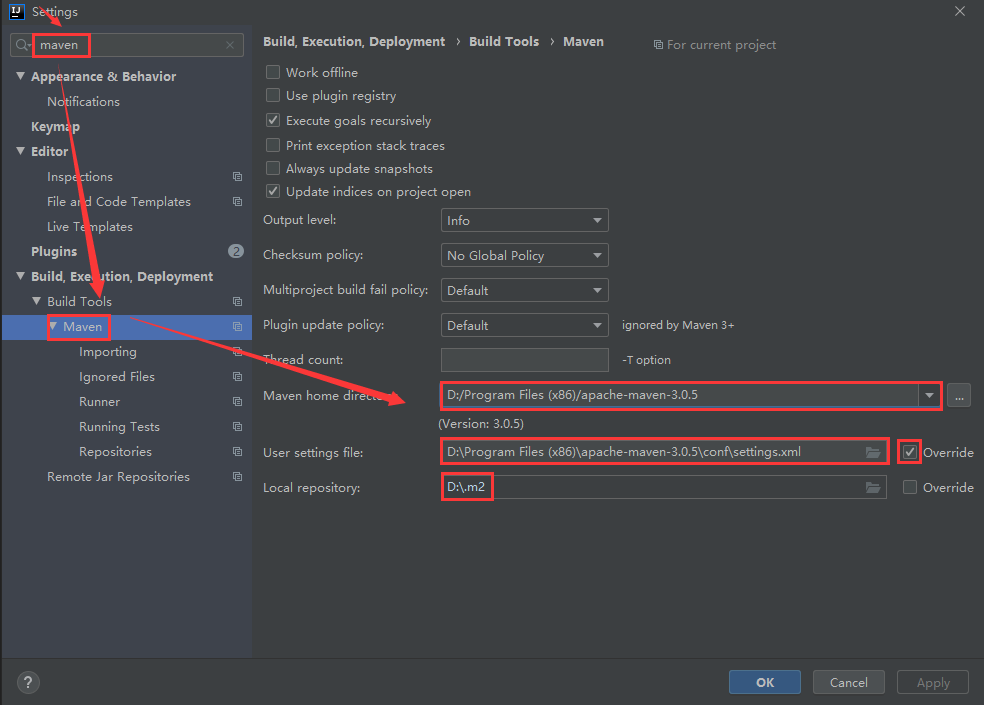
这还没完,还需要在idea中指定我们本地的maven配置
点击idea左上角的File-->Settings,进入如下界面,搜索maven,把本地的maven添加到这里面即可。
下面我们来创建一个maven项目
项目名称为db_hadoop
注意:项目创建好以后,在新打开的界面中需要点击右小角的Enable Auto Import,这样添加到maven依赖会自动引入,否则会发现引入依赖了,但是代码中还是识别不了,这个时候还需要手动引入,比较麻烦。
ok,项目创建好了以后,就需要引入hadoop的依赖了
在这里我们需要引入hadoop-client依赖包,到maven仓库中去找,添加到pom.xml文件中
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
然后创建代码
- 上传文件
package com.imooc.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.FileInputStream;
import java.net.URI;
/**
* Java代码操作HDFS
* 文件操作:上传文件、下载文件、删除文件
* Created by xuwei
*/
public class HdfsOp {
public static void main(String[] args) throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//获取操作HDFS的对象
FileSystem fileSystem = FileSystem.get(conf);
//获取HDFS文件系统的输出流
FSDataOutputStream fos = fileSystem.create(new Path("/user.txt"));
//获取本地文件的输入流
FileInputStream fis = new FileInputStream("D:\\user.txt");
//上传文件:通过工具类把输入流拷贝到输出流里面,实现本地文件上传到HDFS
IOUtils.copyBytes(fis,fos,1024,true);
}
}
执行代码,发现报错,提示权限拒绝,说明windows中的这个用户没有权限向HDFS中写入数据
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=yehua, access=WRITE, inode="/":root:supergroup:drwxr-xr-x
解决办法有两个
第一种:去掉hdfs的用户权限检验机制,通过在hdfs-site.xml中配置dfs.permissions.enabled为false即可
第二种:把代码打包到linux中执行
在这里为了在本地测试方便,我们先使用第一种方式
1:停止Hadoop集群
[root@bigdata01 ~]# cd /data/soft/hadoop-3.2.0
[root@bigdata01 hadoop-3.2.0]# sbin/stop-all.sh
Stopping namenodes on [bigdata01]
Last login: Wed Apr 8 20:25:17 CST 2020 from 192.168.182.1 on pts/1
Stopping datanodes
Last login: Wed Apr 8 20:25:40 CST 2020 on pts/1
Stopping secondary namenodes [bigdata01]
Last login: Wed Apr 8 20:25:41 CST 2020 on pts/1
Stopping nodemanagers
Last login: Wed Apr 8 20:25:44 CST 2020 on pts/1
Stopping resourcemanager
Last login: Wed Apr 8 20:25:47 CST 2020 on pts/1
2:修改hdfs-site.xml配置文件
注意:集群内所有节点中的配置文件都需要修改,先在bigdata01节点上修改,然后再同步到另外两个节点上
在bigdata01上操作
[root@bigdata01 hadoop-3.2.0]# vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:50090</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
同步到另外两个节点中
[root@bigdata01 hadoop-3.2.0]# scp -rq etc/hadoop/hdfs-site.xml bigdata02:/data/soft/hadoop-3.2.0/etc/hadoop/
[root@bigdata01 hadoop-3.2.0]# scp -rq etc/hadoop/hdfs-site.xml bigdata03:/data/soft/hadoop-3.2.0/etc/hadoop/
3:启动Hadoop集群
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
Starting namenodes on [bigdata01]
Last login: Wed Apr 8 20:25:49 CST 2020 on pts/1
Starting datanodes
Last login: Wed Apr 8 20:29:57 CST 2020 on pts/1
Starting secondary namenodes [bigdata01]
Last login: Wed Apr 8 20:29:59 CST 2020 on pts/1
Starting resourcemanager
Last login: Wed Apr 8 20:30:04 CST 2020 on pts/1
Starting nodemanagers
Last login: Wed Apr 8 20:30:10 CST 2020 on pts/1
重新再执行代码,没有报错,到hdfs上查看数据
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
Found 4 items
-rw-r--r-- 2 root supergroup 150569 2020-04-08 15:55 /LICENSE.txt
-rw-r--r-- 2 root supergroup 22125 2020-04-08 15:55 /NOTICE.txt
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:55 /README.txt
-rw-r--r-- 3 yehua supergroup 17 2020-04-08 20:31 /user.txt
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -cat /user.txt
jack
tom
jessic
下面还需要实现其他功能,对代码进行封装提取
package com.imooc.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.FileInputStream;
import java.io.IOException;
import java.net.URI;
/**
* Java代码操作HDFS
* 文件操作:上传文件、下载文件、删除文件
* Created by xuwei
*/
public class HdfsOp {
public static void main(String[] args) throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//获取操作HDFS的对象
FileSystem fileSystem = FileSystem.get(conf);
put(fileSystem);
}
/**
* 文件上传
* @param fileSystem
* @throws IOException
*/
private static void put(FileSystem fileSystem) throws IOException {
//获取HDFS文件系统的输出流
FSDataOutputStream fos = fileSystem.create(new Path("/user.txt"));
//获取本地文件的输入流
FileInputStream fis = new FileInputStream("D:\\user.txt");
//上传文件:通过工具类把输入流拷贝到输出流里面,实现本地文件上传到HDFS
IOUtils.copyBytes(fis,fos,1024,true);
}
}
- 下载文件
执行代码,到windows的D盘验证文件是否生成,如果有就表示执行成功
/**
* 下载文件
* @param fileSystem
* @throws IOException
*/
private static void get(FileSystem fileSystem) throws IOException{
//获取HDFS文件系统的输入流
FSDataInputStream fis = fileSystem.open(new Path("/README.txt"));
//获取本地文件的输出流
FileOutputStream fos = new FileOutputStream("D:\\README.txt");
//下载文件
IOUtils.copyBytes(fis,fos,1024,true);
}
- 删除文件
执行删除操作代码
/**
* 删除文件
* @param fileSystem
* @throws IOException
*/
private static void delete(FileSystem fileSystem) throws IOException{
//删除文件,目录也可以删除
//如果要递归删除目录,则第二个参数需要设置为true
//如果是删除文件或者空目录,第二个参数会被忽略
boolean flag = fileSystem.delete(new Path("/LICENSE.txt"),true);
if(flag){
System.out.println("删除成功!");
}else{
System.out.println("删除失败!");
}
}
然后到hdfs中验证文件是否被删除,从这里可以看出来/LICENSE.txt文件已经被删除
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
Found 3 items
-rw-r--r-- 2 root supergroup 22125 2020-04-08 15:55 /NOTICE.txt
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:55 /README.txt
-rw-r--r-- 3 yehua supergroup 17 2020-04-08 20:31 /user.txt
我们在执行代码的时候会发现输出了很多红色的警告信息,虽然不影响代码执行,但是看起来很碍眼,强迫症实在忍不了
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
log4j:WARN No appenders could be found for logger (org.apache.htrace.core.Tracer).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
如何解决这个问题呢?
通过分析错误信息发现第一个是缺少log4j的实现类,第二个是缺少log4j的配置文件
1:pom.xml中增加log4j依赖
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.10</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.10</version>
</dependency>
2:resources目录下添加log4j.properties文件
在项目的src\main\resources目录中添加log4j.properties
log4j.properties文件内容如下:
log4j.rootLogger=info,stdout
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c] [%p] - %m%n
再执行代码,发现就不会有那些红色的警告信息了。
HDFS体系结构
前面我们掌握了HDFS的基本使用,下面我们来详细分析一下HDFS深层次的内容
HDFS支持主从结构,主节点称为 NameNode ,是因为主节点上运行的有NameNode进程,NameNode支持多个,目前我们的集群中只配置了一个
从节点称为 DataNode ,是因为从节点上面运行的有DataNode进程,DataNode支持多个,目前我们的集群中有两个
HDFS中还包含一个 SecondaryNameNode 进程,这个进程从字面意思上看像是第二个NameNode的意思,其实不是,一会我们会详细分析。
在这大家可以这样理解:
公司BOSS:NameNode
秘书:SecondaryNameNode
员工:DataNode
接着看一下这张图,这就是HDFS的体系结构,这里面的TCP、RPC、HTTP表示是不同的网络通信方式,通过这张图是想加深大家对HDFS体系结构的理解,我们前面配置的集群NameNode和SecondaryNameNode进程在同一台机器上面,在这个图里面是把它们分开到多台机器中了。
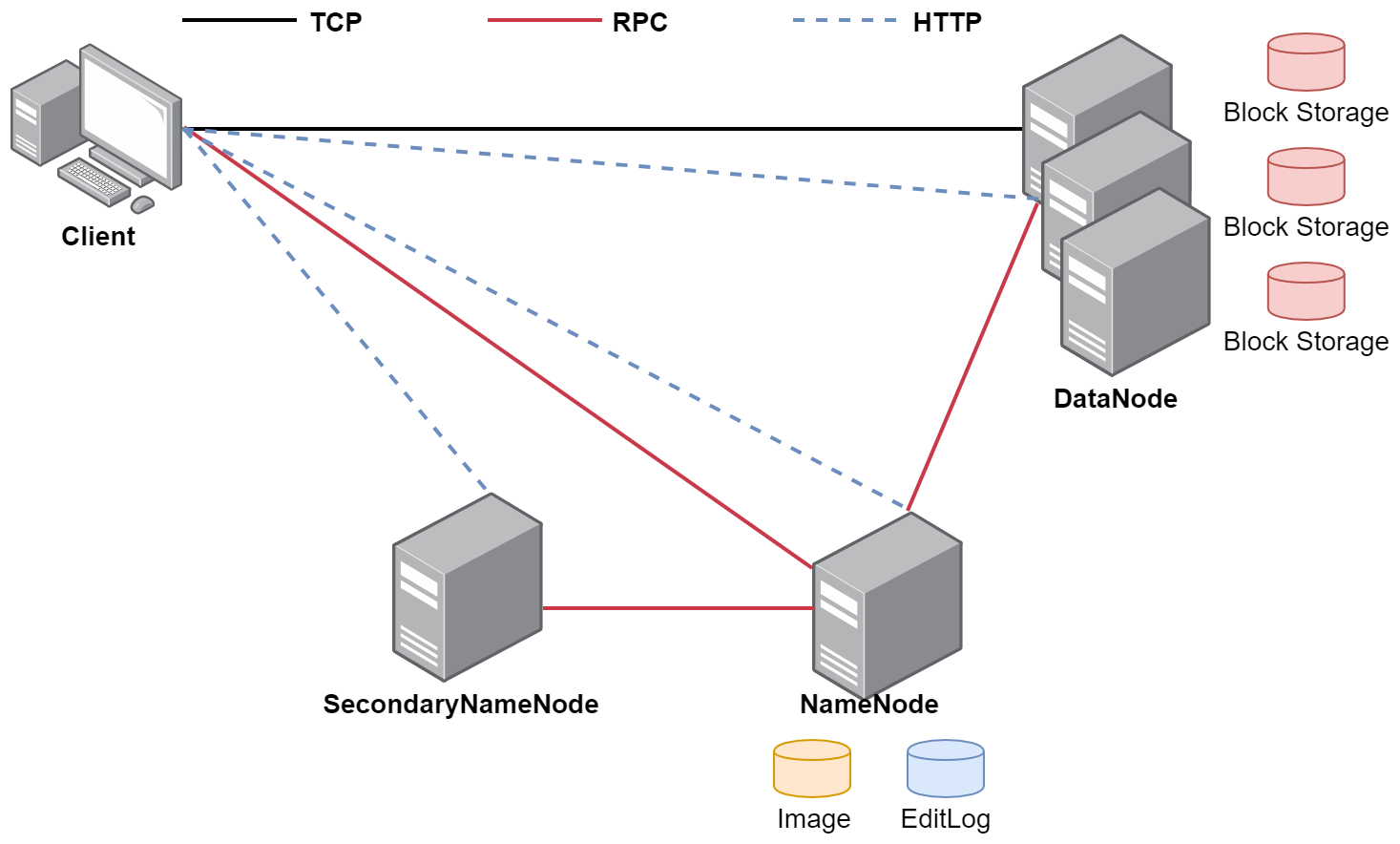
那接下来我们就详细分析这里面的每一个进程。
NameNode介绍
首先是NameNode,NameNode是整个文件系统的管理节点
它主要维护着整个文件系统的文件目录树,文件/目录的信息 和 每个文件对应的数据块列表,并且还负责接收用户的操作请求
目录树:表示目录之间的层级关系,就是我们在hdfs上执行ls命令可以看到的那个目录结构信息。
文件/目录的信息:表示文件/目录的的一些基本信息,所有者 属组 修改时间 文件大小等信息
每个文件对应的数据块列表:如果一个文件太大,那么在集群中存储的时候会对文件进行切割,这个时候就类似于会给文件分成一块一块的,存储到不同机器上面。所以HDFS还要记录一下一个文件到底被分了多少块,每一块都在什么地方存储着
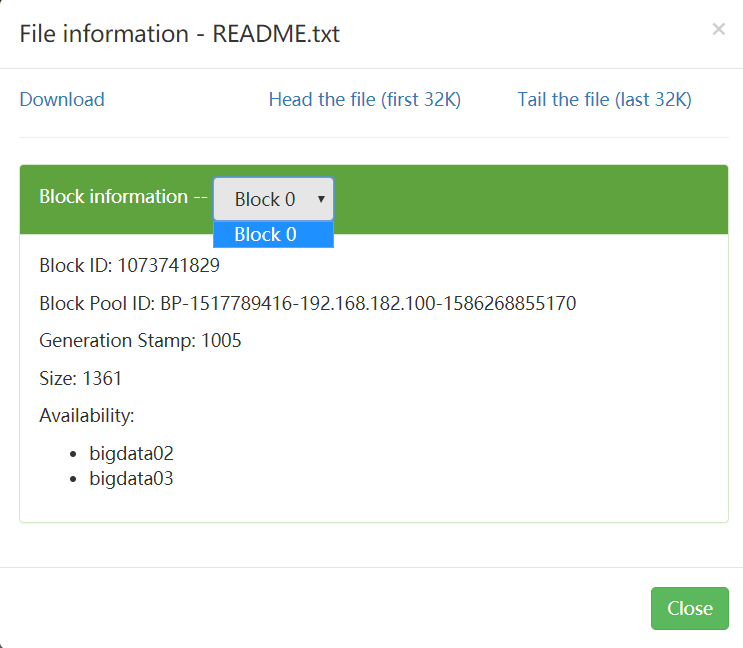
我们现在可以到集群的9870界面查看一下,随便找一个文件看一下,点击文件名称,可以看到Block information 但是文件太小,只有一个块 叫Block 0
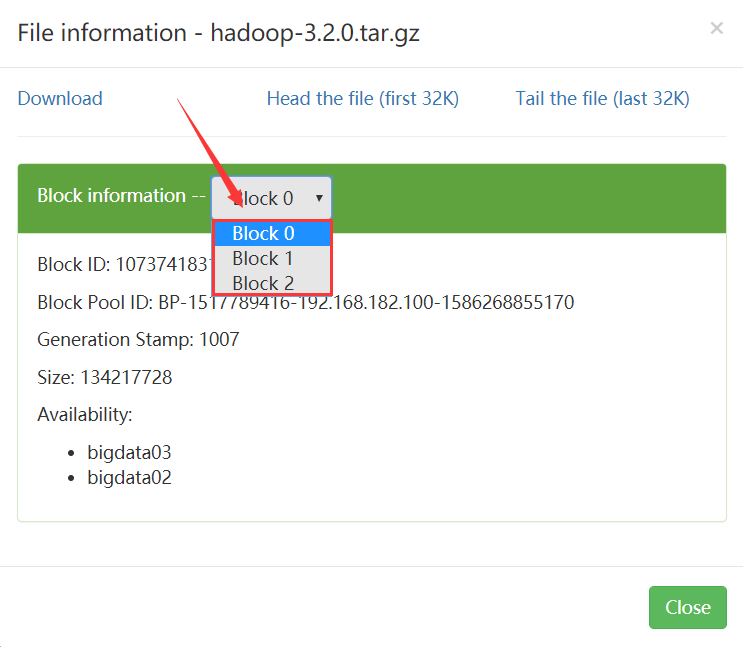
我们试着上传一个大一点的文件,找一个200M左右的文件。
[root@bigdata01 hadoop-3.2.0]# cd /data/soft/
[root@bigdata01 soft]# hdfs dfs -put hadoop-3.2.0.tar.gz /
这个时候再去看 就能看到分成了多个Block块,一个文件对应有多少个Block块信息 是在namenode里面保存着的
- 接收用户的操作请求:其实我们在命令行使用hdfs操作的时候,是需要先和namenode通信 才能开始去操作数据的。
为什么呢?
因为文件信息都在namenode上面存储着的
namenode是非常重要的,它的这些信息最终是会存储到文件上的,那接下来我们来看一下NameNode中包含的那些文件
NameNode主要包括以下文件:
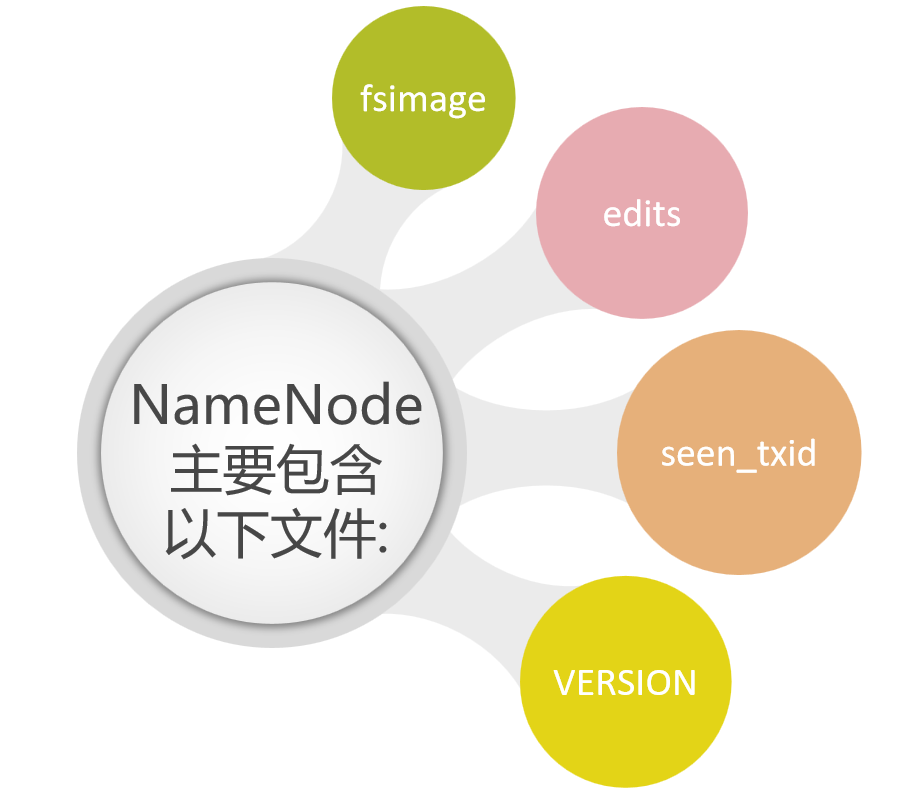
这些文件所在的路径是由hdfs-default.xml的dfs.namenode.name.dir属性控制的
hdfs-default.xml文件在哪呢?
它在hadoop-3.2.0\share\hadoop\hdfs\hadoop-hdfs-3.2.0.jar中,这个文件中包含了HDFS相关的所有默认参数,咱们在配置集群的时候会修改一个hdfs-site.xml文件,hdfs-site.xml文件属于hdfs-default.xml的一个扩展,它可以覆盖掉hdfs-default.xml中同名的参数。
那我们来看一下这个文件中的dfs.namenode.name.dir属性
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
<description>Determines where on the local filesystem the DFS name node
should store the name table(fsimage). If this is a comma-delimited list
of directories then the name table is replicated in all of the
directories, for redundancy. </description>
</property>
这个属性的值是由hadoop.tmp.dir属性控制的,这个属性的值默认在core-default.xml文件中。大家还有没有印象,我们在修改core-site.xml的时候设置的有hadoop.tmp.dir属性的值,值是/data/hadoop_repo,所以说core-site.xml中的hadoop.tmp.dir属性会覆盖掉core-default.xml中的值
最终dfs.namenode.name.dir属性的值就是:/data/hadoop_repo/dfs/name
那我们到bigdata01节点上看一下
进入到/data/hadoop_repo/dfs/name目录下
发现这个下面会有一个current 目录,表示当前的意思,还有一个in_use.lock 这个只是一个普通文件,但是它其实有特殊的含义,你看他的文件名后缀值lock 表示是锁的意思,文件名是in_use 表示这个文件现在正在使用,不允许你再启动namenode。
当我们启动namonde的时候 会判断这个目录下是否有in_use.lock 这个相当于一把锁,如果没有的话,才可以启动成功,启动成功之后就会加一把锁, 停止的时候会把这个锁去掉
[root@bigdata01 name]# cd /data/hadoop_repo/dfs/name
[root@bigdata01 name]# ll
total 8
drwxr-xr-x. 2 root root 4096 Apr 8 21:31 current
-rw-r--r--. 1 root root 14 Apr 8 20:30 in_use.lock
[root@bigdata01 name]# cd current
[root@bigdata01 current]# ll
total 4152
-rw-r--r--. 1 root root 42 Apr 7 22:17 edits_0000000000000000001-0000000000000000002
-rw-r--r--. 1 root root 1048576 Apr 7 22:17 edits_0000000000000000003-0000000000000000003
-rw-r--r--. 1 root root 42 Apr 7 22:22 edits_0000000000000000004-0000000000000000005
-rw-r--r--. 1 root root 1048576 Apr 7 22:22 edits_0000000000000000006-0000000000000000006
-rw-r--r--. 1 root root 42 Apr 8 14:53 edits_0000000000000000007-0000000000000000008
-rw-r--r--. 1 root root 1644 Apr 8 15:53 edits_0000000000000000009-0000000000000000031
-rw-r--r--. 1 root root 1523 Apr 8 16:53 edits_0000000000000000032-0000000000000000051
-rw-r--r--. 1 root root 42 Apr 8 17:53 edits_0000000000000000052-0000000000000000053
-rw-r--r--. 1 root root 1048576 Apr 8 17:53 edits_0000000000000000054-0000000000000000054
-rw-r--r--. 1 root root 42 Apr 8 20:31 edits_0000000000000000055-0000000000000000056
-rw-r--r--. 1 root root 523 Apr 8 21:31 edits_0000000000000000057-0000000000000000065
-rw-r--r--. 1 root root 1048576 Apr 8 21:31 edits_inprogress_0000000000000000066
-rw-r--r--. 1 root root 652 Apr 8 20:31 fsimage_0000000000000000056
-rw-r--r--. 1 root root 62 Apr 8 20:31 fsimage_0000000000000000056.md5
-rw-r--r--. 1 root root 661 Apr 8 21:31 fsimage_0000000000000000065
-rw-r--r--. 1 root root 62 Apr 8 21:31 fsimage_0000000000000000065.md5
-rw-r--r--. 1 root root 3 Apr 8 21:31 seen_txid
-rw-r--r--. 1 root root 219 Apr 8 20:30 VERSION
里面有edits文件 和fsimage文件
fsimage文件有两个文件名相同的,有一个后缀是md5 md5是一种加密算法,这个其实主要是为了做md5校验的,为了保证文件传输的过程中不出问题,相同内容的md5是一样的,所以后期如果我把这个fsimage和对应的fsimage.md5发给你 然后你根据md5对fsimage的内容进行加密,获取一个值 和fsimage.md5中的内容进行比较,如果一样,说明你接收到的文件就是完整的。
我们在网站下载一些软件的时候 也会有一些md5文件,方便验证下载的文件是否完整。
在这里可以把fsimage 拆开 fs 是文件系统 filesystem image是镜像
说明是文件系统镜像,就是给文件照了一个像,把文件的当前信息记录下来
我们可以看一下这个文件,这个文件需要使用特殊的命令进行查看
-i 输入文件 -o 输出文件
[root@bigdata01 current]# hdfs oiv -p XML -i fsimage_0000000000000000056 -o fsimage56.xml
2020-04-08 22:23:32,851 INFO offlineImageViewer.FSImageHandler: Loading 4 strings
2020-04-08 22:23:32,916 INFO namenode.FSDirectory: GLOBAL serial map: bits=29 maxEntries=536870911
2020-04-08 22:23:32,916 INFO namenode.FSDirectory: USER serial map: bits=24 maxEntries=16777215
2020-04-08 22:23:32,916 INFO namenode.FSDirectory: GROUP serial map: bits=24 maxEntries=16777215
2020-04-08 22:23:32,916 INFO namenode.FSDirectory: XATTR serial map: bits=24 maxEntries=16777215
把fsimage56.xml这个文件拉取到window上,查看比较方便
<?xml version="1.0"?>
<fsimage><version><layoutVersion>-65</layoutVersion><onDiskVersion>1</onDiskVersion><oivRevision>e97acb3bd8f3befd27418996fa5d4b50bf2e17bf</oivRevision></version>
<NameSection><namespaceId>498554338</namespaceId><genstampV1>1000</genstampV1><genstampV2>1005</genstampV2><genstampV1Limit>0</genstampV1Limit><lastAllocatedBlockId>1073741829</lastAllocatedBlockId><txid>56</txid></NameSection>
<ErasureCodingSection>
<erasureCodingPolicy>
<policyId>5</policyId><policyName>RS-10-4-1024k</policyName><cellSize>1048576</cellSize><policyState>DISABLED</policyState><ecSchema>
<codecName>rs</codecName><dataUnits>10</dataUnits><parityUnits>4</parityUnits></ecSchema>
</erasureCodingPolicy>
<erasureCodingPolicy>
<policyId>2</policyId><policyName>RS-3-2-1024k</policyName><cellSize>1048576</cellSize><policyState>DISABLED</policyState><ecSchema>
<codecName>rs</codecName><dataUnits>3</dataUnits><parityUnits>2</parityUnits></ecSchema>
</erasureCodingPolicy>
<erasureCodingPolicy>
<policyId>1</policyId><policyName>RS-6-3-1024k</policyName><cellSize>1048576</cellSize><policyState>ENABLED</policyState><ecSchema>
<codecName>rs</codecName><dataUnits>6</dataUnits><parityUnits>3</parityUnits></ecSchema>
</erasureCodingPolicy>
<erasureCodingPolicy>
<policyId>3</policyId><policyName>RS-LEGACY-6-3-1024k</policyName><cellSize>1048576</cellSize><policyState>DISABLED</policyState><ecSchema>
<codecName>rs-legacy</codecName><dataUnits>6</dataUnits><parityUnits>3</parityUnits></ecSchema>
</erasureCodingPolicy>
<erasureCodingPolicy>
<policyId>4</policyId><policyName>XOR-2-1-1024k</policyName><cellSize>1048576</cellSize><policyState>DISABLED</policyState><ecSchema>
<codecName>xor</codecName><dataUnits>2</dataUnits><parityUnits>1</parityUnits></ecSchema>
</erasureCodingPolicy>
</ErasureCodingSection>
<INodeSection><lastInodeId>16395</lastInodeId><numInodes>4</numInodes><inode><id>16385</id><type>DIRECTORY</type><name></name><mtime>1586332531935</mtime><permission>root:supergroup:0755</permission><nsquota>9223372036854775807</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16393</id><type>FILE</type><name>LICENSE.txt</name><replication>2</replication><mtime>1586332513657</mtime><atime>1586332513485</atime><preferredBlockSize>134217728</preferredBlockSize><permission>root:supergroup:0644</permission><blocks><block><id>1073741827</id><genstamp>1003</genstamp><numBytes>150569</numBytes></block>
</blocks>
<storagePolicyId>0</storagePolicyId></inode>
<inode><id>16394</id><type>FILE</type><name>NOTICE.txt</name><replication>2</replication><mtime>1586332522962</mtime><atime>1586332522814</atime><preferredBlockSize>134217728</preferredBlockSize><permission>root:supergroup:0644</permission><blocks><block><id>1073741828</id><genstamp>1004</genstamp><numBytes>22125</numBytes></block>
</blocks>
<storagePolicyId>0</storagePolicyId></inode>
<inode><id>16395</id><type>FILE</type><name>README.txt</name><replication>2</replication><mtime>1586332531932</mtime><atime>1586332531689</atime><preferredBlockSize>134217728</preferredBlockSize><permission>root:supergroup:0644</permission><blocks><block><id>1073741829</id><genstamp>1005</genstamp><numBytes>1361</numBytes></block>
</blocks>
<storagePolicyId>0</storagePolicyId></inode>
</INodeSection>
<INodeReferenceSection></INodeReferenceSection><SnapshotSection><snapshotCounter>0</snapshotCounter><numSnapshots>0</numSnapshots></SnapshotSection>
<INodeDirectorySection><directory><parent>16385</parent><child>16393</child><child>16394</child><child>16395</child></directory>
</INodeDirectorySection>
<FileUnderConstructionSection></FileUnderConstructionSection>
<SecretManagerSection><currentId>0</currentId><tokenSequenceNumber>0</tokenSequenceNumber><numDelegationKeys>0</numDelegationKeys><numTokens>0</numTokens></SecretManagerSection><CacheManagerSection><nextDirectiveId>1</nextDirectiveId><numDirectives>0</numDirectives><numPools>0</numPools></CacheManagerSection>
</fsimage>
里面最外层是一个fsimage标签,看里面的inode标签,
这个inode表示是hdfs中的每一个目录或者文件信息
例如这个:
<inode><id>16393</id><type>FILE</type><name>LICENSE.txt</name><replication>2</replication><mtime>1586332513657</mtime><atime>1586332513485</atime><preferredBlockSize>134217728</preferredBlockSize><permission>root:supergroup:0644</permission><blocks><block><id>1073741827</id><genstamp>1003</genstamp><numBytes>150569</numBytes></block>
</blocks>
<storagePolicyId>0</storagePolicyId></inode>
id:唯一编号
type:文件类型
name:文件名称
replication:文件的副本数量
mtime:修改时间
atime:访问时间
preferredBlockSize:推荐每一个数据块的大小
permission:权限信息
blocks:包含多少数据块【文件被切成数据块】
block:内部的id表示是块id,genstamp是一个唯一编号,numBytes表示当前数据块的实际大小,storagePolicyId表示是数据的存储策略
这个文件中其实就维护了整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表,所以说fsimage中存放了hdfs最核心的数据。
下面我们来看一下edits文件,这些文件在这称之为事务文件,为什么呢?
当我们上传一个文件的时候,上传一个10G的文件,假设传到9G的时候上传失败了,这个时候就需要重新传,那hdfs怎么知道这个文件失败了呢?这个是在edits文件中记录的。
当我们上传大文件的时候,一个大文件会分为多个block,那么edits文件中就会记录这些block的上传状态,只有当全部block都上传成功了以后,这个时候edits中才会记录这个文件上传成功了,那么我们执行hdfs dfs -ls 的时候就能查到这个文件了,
所以当我们在hdfs中执行ls命令的时候,其实会查询fsimage和edits中的内容
为什么会有这两个文件呢?
首先,我们固化的一些文件内容是存储在fsimage文件中,当前正在上传的文件信息是存储在edits文件中。 这个时候我们来查看一下这个edits文件的内容,挑一个edits文件内容多一些的文件
[root@bigdata01 current]# hdfs oev -i edits_0000000000000000057-0000000000000000065 -o edits.xml
分析生成的edits.xml文件,这个地方注意,可能有的edits文件生成的edits.xml为空,需要多试几个。
这个edits.xml中可以大致看一下,里面有很多record。每一个record代表不同的操作,
例如 OP_ADD,OP_CLOSE 等等,具体挑一个实例进行分析。
OP_ADD:执行上传操作
OP_ALLOCATE_BLOCK_ID:申请block块id
OP_SET_GENSTAMP_V2:设置GENSTAMP
OP_ADD_BLOCK:添加block块
OP_CLOSE:关闭上传操作
<RECORD>
<OPCODE>OP_ADD</OPCODE>
<DATA>
<TXID>58</TXID>
<LENGTH>0</LENGTH>
<INODEID>16396</INODEID>
<PATH>/user.txt</PATH>
<REPLICATION>3</REPLICATION>
<MTIME>1586349095694</MTIME>
<ATIME>1586349095694</ATIME>
<BLOCKSIZE>134217728</BLOCKSIZE>
<CLIENT_NAME>DFSClient_NONMAPREDUCE_-1768454371_1</CLIENT_NAME>
<CLIENT_MACHINE>192.168.182.1</CLIENT_MACHINE>
<OVERWRITE>true</OVERWRITE>
<PERMISSION_STATUS>
<USERNAME>yehua</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>420</MODE>
</PERMISSION_STATUS>
<ERASURE_CODING_POLICY_ID>0</ERASURE_CODING_POLICY_ID>
<RPC_CLIENTID>1722b83a-2dc7-4c46-baa9-9fa956b755cd</RPC_CLIENTID>
<RPC_CALLID>0</RPC_CALLID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE>
<DATA>
<TXID>59</TXID>
<BLOCK_ID>1073741830</BLOCK_ID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_GENSTAMP_V2</OPCODE>
<DATA>
<TXID>60</TXID>
<GENSTAMPV2>1006</GENSTAMPV2>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ADD_BLOCK</OPCODE>
<DATA>
<TXID>61</TXID>
<PATH>/user.txt</PATH>
<BLOCK>
<BLOCK_ID>1073741830</BLOCK_ID>
<NUM_BYTES>0</NUM_BYTES>
<GENSTAMP>1006</GENSTAMP>
</BLOCK>
<RPC_CLIENTID/>
<RPC_CALLID>-2</RPC_CALLID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_CLOSE</OPCODE>
<DATA>
<TXID>62</TXID>
<LENGTH>0</LENGTH>
<INODEID>0</INODEID>
<PATH>/user.txt</PATH>
<REPLICATION>3</REPLICATION>
<MTIME>1586349096480</MTIME>
<ATIME>1586349095694</ATIME>
<BLOCKSIZE>134217728</BLOCKSIZE>
<CLIENT_NAME/>
<CLIENT_MACHINE/>
<OVERWRITE>false</OVERWRITE>
<BLOCK>
<BLOCK_ID>1073741830</BLOCK_ID>
<NUM_BYTES>17</NUM_BYTES>
<GENSTAMP>1006</GENSTAMP>
</BLOCK>
<PERMISSION_STATUS>
<USERNAME>yehua</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>420</MODE>
</PERMISSION_STATUS>
</DATA>
</RECORD>
这里面的每一个record都有一个事务id,txid,事务id是连续的,其实一个put操作会在edits文件中产生很多的record,对应的就是很多步骤,这些步骤对我们是屏蔽的。
注意了,根据我们刚才的分析,我们所有对hdfs的增删改操作都会在edits文件中留下信息,那么fsimage文件中的内容是从哪来的?
其实是这样的,edits文件会定期合并到fsimage文件中。
有同学可能有疑问了,edits文件和fsimage文件中的内容是不一样的,这怎么能是合并出来的呢?
注意,这个其实是框架去做的,在合并的时候会对edits中的内容进行转换,生成新的内容,其实edits中保存的内容是不是太细了,单单一个上传操作就分为了好几步,其实上传成功之后,我们只需要保存文件具体存储的block信息就行了把,所以在合并的时候其实是对edits中的内容进行了精简。
他们具体合并的代码我们不用太过关注,但是我们要知道是那个进程去做的这个事情,
其实就是我们之前提到的secondarynamenode
这个进程就是负责定期的把edits中的内容合并到fsimage中。他只做一件事,这是一个单独的进程,在实际工作中部署的时候,也需要部署到一个单独的节点上面。
current目录中还有一个seentxid文件,HDFS format之后是0,它代表的是namenode里面的edits*文件的尾数,namenode重启的时候,会按照seen_txid的数字,顺序从头跑edits_0000001~到seen_txid的数字。如果根据对应的seen_txid无法加载到对应的文件,NameNode进程将不会完成启动以保护数据一致性。
[root@bigdata01 current]# cat seen_txid
66
最后这个current目录下面还有一个VERSION文件
[root@bigdata01 current]# cat VERSION
#Wed Apr 08 20:30:00 CST 2020
namespaceID=498554338
clusterID=CID-cc0792dd-a861-4a3f-9151-b0695e4c7e70
cTime=1586268855170
storageType=NAME_NODE
blockpoolID=BP-1517789416-192.168.182.100-1586268855170
layoutVersion=-65
这里面显示的集群的一些信息、当重新对hdfs格式化 之后,这里面的信息会变化。
之前我们说过 在使用hdfs的时候只格式化一次,不要格式化多次,为什么呢?
一会在讲datanode的时候会详细解释、
最后做一个总结:
fsimage: 元数据镜像文件,存储某一时刻NameNode内存中的元数据信息,就类似是定时做了一个快照操作。【这里的元数据信息是指文件目录树、文件/目录的信息、每个文件对应的数据块列表】
edits: 操作日志文件【事务文件】,这里面会实时记录用户的所有操作
seentxid: 是存放transactionId的文件,format之后是0,它代表的是namenode里面的edits*文件的尾数,namenode重启的时候,会按照seen_txid的数字,顺序从头跑edits_0000001~到seen_txid的数字。如果根据对应的seen_txid无法加载到对应的文件,NameNode进程将不会完成启动以保护数据一致性。
VERSION:保存了集群的版本信息
SecondaryNameNode介绍
刚才在分析edits日志文件的时候我们已经针对SecondaryNameNode做了介绍,在这里再做一个总结,以示重视。
SecondaryNameNode主要负责定期的把edits文件中的内容合并到fsimage中
这个合并操作称为checkpoint,在合并的时候会对edits中的内容进行转换,生成新的内容保存到fsimage文件中。
注意:在NameNode的HA架构中没有SecondaryNameNode进程,文件合并操作会由standby NameNode负责实现
所以在Hadoop集群中,SecondaryNameNode进程并不是必须的。
DataNode介绍
DataNode是提供真实文件数据的存储服务
针对datanode主要掌握两个概念,一个是block,一个是replication
首先是block
HDFS会按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block,HDFS默认Block大小是 128MB
Blokc块是HDFS读写数据的基本单位,不管你的文件是文本文件 还是视频 或者音频文件,针对hdfs而言 都是字节。
我们之前上传的一个user.txt文件,他的block信息可以在fsimage文件中看到,也可以在hdfs webui上面看到, 里面有block的id信息,并且也会显示这个数据在哪个节点上面

这里显示在bigdata02和bigdata03上面都有,那我们过去看一下,datanode中数据的具体存储位置是由dfs.datanode.data.dir来控制的,通过查询hdfs-default.xml可以知道,具体的位置在这里
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
<description>Determines where on the local filesystem an DFS data node
should store its blocks. If this is a comma-delimited
list of directories, then data will be stored in all named
directories, typically on different devices. The directories should be tagged
with corresponding storage types ([SSD]/[DISK]/[ARCHIVE]/[RAM_DISK]) for HDFS
storage policies. The default storage type will be DISK if the directory does
not have a storage type tagged explicitly. Directories that do not exist will
be created if local filesystem permission allows.
</description>
</property>
那我们连接到bigdata02这个节点上去看一下
[root@bigdata02 ~]# cd /data/hadoop_repo/dfs/data/
[root@bigdata02 data]# ll
total 4
drwxr-xr-x. 3 root root 72 Apr 7 22:21 current
-rw-r--r--. 1 root root 14 Apr 8 20:30 in_use.lock
然后进入current目录,继续一路往下走
[root@bigdata02 data]# cd current/
[root@bigdata02 current]# ll
total 4
drwx------. 4 root root 54 Apr 8 20:30 BP-1517789416-192.168.182.100-1586268855170
-rw-r--r--. 1 root root 229 Apr 8 20:30 VERSION
[root@bigdata02 current]# cd BP-1517789416-192.168.182.100-1586268855170/
[root@bigdata02 BP-1517789416-192.168.182.100-1586268855170]# ll
total 4
drwxr-xr-x. 4 root root 64 Apr 8 20:25 current
-rw-r--r--. 1 root root 166 Apr 7 22:21 scanner.cursor
drwxr-xr-x. 2 root root 6 Apr 8 20:30 tmp
[root@bigdata02 BP-1517789416-192.168.182.100-1586268855170]# cd current/
[root@bigdata02 current]# ll
total 8
-rw-r--r--. 1 root root 20 Apr 8 20:25 dfsUsed
drwxr-xr-x. 3 root root 21 Apr 8 15:34 finalized
drwxr-xr-x. 2 root root 6 Apr 8 22:13 rbw
-rw-r--r--. 1 root root 146 Apr 8 20:30 VERSION
[root@bigdata02 current]# cd finalized/
[root@bigdata02 finalized]# ll
total 0
drwxr-xr-x. 3 root root 21 Apr 8 15:34 subdir0
[root@bigdata02 finalized]# cd subdir0/
[root@bigdata02 subdir0]# ll
total 4
drwxr-xr-x. 2 root root 4096 Apr 8 22:13 subdir0
[root@bigdata02 subdir0]# cd subdir0/
[root@bigdata02 subdir0]# ll
total 340220
-rw-r--r--. 1 root root 22125 Apr 8 15:55 blk_1073741828
-rw-r--r--. 1 root root 183 Apr 8 15:55 blk_1073741828_1004.meta
-rw-r--r--. 1 root root 1361 Apr 8 15:55 blk_1073741829
-rw-r--r--. 1 root root 19 Apr 8 15:55 blk_1073741829_1005.meta
-rw-r--r--. 1 root root 17 Apr 8 20:31 blk_1073741830
-rw-r--r--. 1 root root 11 Apr 8 20:31 blk_1073741830_1006.meta
-rw-r--r--. 1 root root 134217728 Apr 8 22:13 blk_1073741831
-rw-r--r--. 1 root root 1048583 Apr 8 22:13 blk_1073741831_1007.meta
-rw-r--r--. 1 root root 134217728 Apr 8 22:13 blk_1073741832
-rw-r--r--. 1 root root 1048583 Apr 8 22:13 blk_1073741832_1008.meta
-rw-r--r--. 1 root root 77190019 Apr 8 22:13 blk_1073741833
-rw-r--r--. 1 root root 603055 Apr 8 22:13 blk_1073741833_1009.meta
这里面就有很多的block块了,
注意: 这里面的.meta文件也是做校验用的。
根据前面看到的blockid信息到这对应的找到文件,可以直接查看,发现文件内容就是我们之前上传上去的内容。
[root@bigdata02 subdir0]# cat blk_1073741830
jack
tom
jessic
[root@bigdata02 subdir0]#
注意:这个block中的内容可能只是文件的一部分,如果你的文件较大的话,就会分为多个block存储,默认 hadoop3中一个block的大小为128M。根据字节进行截取,截取到128M就是一个block。如果文件大小没有默认的block块大,那最终就只有一个block。
HDFS中,如果一个文件小于一个数据块的大小,那么并不会占用整个数据块的存储空间
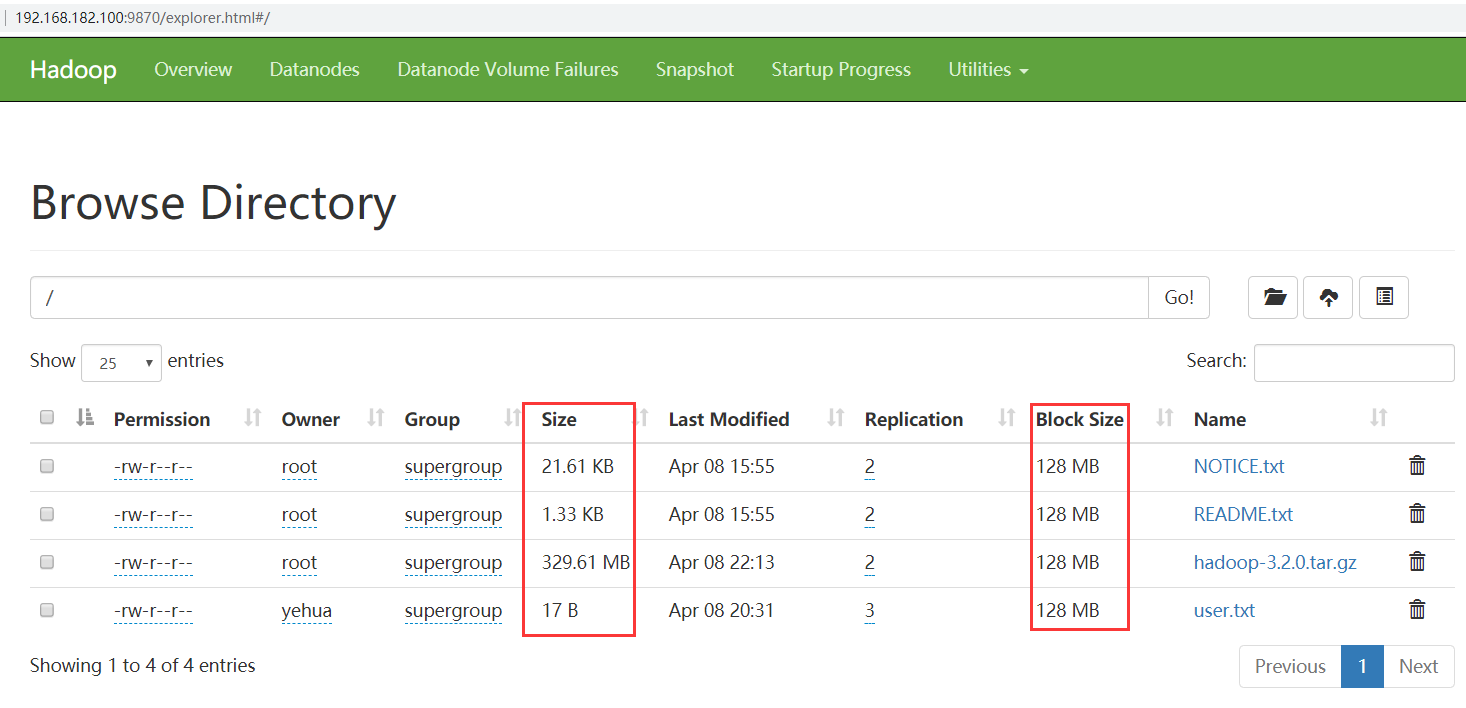
size是表示我们上传文件的实际大小,blocksize是指文件的最大块大小。
注意;这个block块是hdfs产生的,如果我们直接把文件上传到这个block文件所在的目录,这个时候hdfs是不识别的,没有用的
假设我们上传了两个10M的文件 又上传了一个200M的文件
问1:会产生多少个block块? 4个
问2:在hdfs中会显示几个文件?3个
下面看一下副本,副本表示数据有多少个备份
我们现在的集群有两个从节点,所以最多可以有2个备份,这个是在hdfs-site.xml中进行配置的,dfs.replication
默认这个参数的配置是3。表示会有3个副本。
副本只有一个作用就是保证数据安全。
NameNode总结
注意:block块存放在哪些datanode上,只有datanode自己知道,当集群启动的时候,datanode会扫描自己节点上面的所有block块信息,然后把节点和这个节点上的所有block块信息告诉给namenode。这个关系是每次重启集群都会动态加载的【这个其实就是集群为什么数据越多,启动越慢的原因】
咱们之前说的fsimage(edits)文件中保存的有文件和block块之间的信息。
这里说的是block块和节点之间的关系,这两块关联在一起之后,就可以根据文件找到对应的block块,再根据block块找到对应的datanode节点,这样就真正找到了数据。
所以说 其实namenode中不仅维护了文件和block块的信息 还维护了block块和所在的datanode节点的信息。
可以理解为namenode维护了两份关系:
第一份关系:file 与block list的关系,对应的关系信息存储在fsimage和edits文件中,当NameNode启动的时候会把文件中的元数据信息加载到内存中
第二份关系:datanode与block的关系,对应的关系主要在集群启动的时候保存在内存中,当DataNode启动时会把当前节点上的Block信息和节点信息上报给NameNode
注意了,刚才我们说了NameNode启动的时候会把文件中的元数据信息加载到内存中,然后每一个文件的元数据信息会占用150字节的内存空间,这个是恒定的,和文件大小没有关系,咱们前面在介绍HDFS的时候说过,HDFS不适合存储小文件,其实主要原因就在这里,不管是大文件还是小文件,一个文件的元数据信息在NameNode中都会占用150字节,NameNode节点的内存是有限的,所以它的存储能力也是有限的,如果我们存储了一堆都是几KB的小文件,最后发现NameNode的内存占满了,确实存储了很多文件,但是文件的总体大小却很小,这样就失去了HDFS存在的价值
最后,在datanode的数据目录下面的current目录中也有一个VERSION文件
这个VERSION和namenode的VERSION文件是有一些相似之处的,我们来具体对比一下两个文件的内容。
namenode的VERSION文件
[root@bigdata01 current]# cat VERSION
#Wed Apr 08 20:30:00 CST 2020
namespaceID=498554338
clusterID=CID-cc0792dd-a861-4a3f-9151-b0695e4c7e70
cTime=1586268855170
storageType=NAME_NODE
blockpoolID=BP-1517789416-192.168.182.100-1586268855170
layoutVersion=-65
datanode的VERSION文件
[root@bigdata02 current]# cat VERSION
#Wed Apr 08 20:30:04 CST 2020
storageID=DS-0e86cd27-4961-4526-bacb-3b692a90b1b0
clusterID=CID-cc0792dd-a861-4a3f-9151-b0695e4c7e70
cTime=0
datanodeUuid=0b09f3d7-442d-4e28-b3cc-2edb0991bae3
storageType=DATA_NODE
layoutVersion=-57
我们前面说了namenode不要随便格式化,因为格式化了以后VERSION里面的clusterID会变,但是datanode的VERSION中的clusterID并没有变,所以就对应不上了。
咱们之前说过如果确实要重新格式化的话需要把/data/hadoop_repo数据目录下的内容都清空,全部都重新生成是可以的。
HDFS的回收站
我们windows系统里面有一个回收站,当想恢复删除的文件的话就可以到这里面进行恢复,HDFS也有回收站。
HDFS会为每一个用户创建一个回收站目录:/user/用户名/.Trash/,每一个被用户在Shell命令行删除的文件/目录,会进入到对应的回收站目录中,在回收站中的数据都有一个生存周期,也就是当回收站中的文件/目录在一段时间之内没有被用户恢复的话,HDFS就会自动的把这个文件/目录彻底删除,之后,用户就永远也找不回这个文件/目录了。
默认情况下hdfs的回收站是没有开启的,需要通过一个配置来开启,在core-site.xml中添加如下配置,value的单位是分钟,1440分钟表示是一天的生存周期
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
在修改配置信息之前先验证一下删除操作,显示的是直接删除掉了。
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r /NOTICE.txt
Deleted /NOTICE.txt
修改回收站配置,先在bigdata01上操作,然后再同步到其它两个节点,先停止集群
[root@bigdata01 hadoop-3.2.0]# sbin/stop-all.sh
[root@bigdata01 hadoop-3.2.0]# vi etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_repo</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
[root@bigdata01 hadoop-3.2.0]# scp -rq etc/hadoop/core-site.xml bigdata02:/data/soft/hadoop-3.2.0/etc/hadoop/
[root@bigdata01 hadoop-3.2.0]# scp -rq etc/hadoop/core-site.xml bigdata03:/data/soft/hadoop-3.2.0/etc/hadoop/
启动集群,再执行删除操作
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r /README.txt
2020-04-09 11:43:47,664 INFO fs.TrashPolicyDefault: Moved: 'hdfs://bigdata01:9000/README.txt' to trash at: hdfs://bigdata01:9000/user/root/.Trash/Current/README.txt
此时看到提示信息说把删除的文件移到到了指定目录中,其实就是移动到了当前用户的回收站目录。
回收站的文件也是可以下载到本地的。其实在这回收站只是一个具备了特殊含义的HDFS目录。
注意:如果删除的文件过大,超过回收站大小的话会提示删除失败 需要指定参数 -skipTrash ,指定这个参数表示删除的文件不会进回收站
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r -skipTrash /user.txt
Deleted /user.txt
HDFS的安全模式
大家在平时操作HDFS的时候,有时候可能会遇到这个问题,特别是刚启动集群的时候去上传或者删除文件,会发现报错,提示NameNode处于safe mode。
这个属于HDFS的安全模式,因为在集群每次重新启动的时候,HDFS都会检查集群中文件信息是否完整,例如副本是否缺少之类的信息,所以这个时间段内是不允许对集群有修改操作的,如果遇到了这个情况,可以稍微等一会,等HDFS自检完毕,就会自动退出安全模式。
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r /hadoop-3.2.0.tar.gz
2020-04-09 12:00:36,646 WARN fs.TrashPolicyDefault: Can't create trash directory: hdfs://bigdata01:9000/user/root/.Trash/Current
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /user/root/.Trash/Current. Name node is in safe mode.
此时访问HDFS的web ui界面,可以看到下面信息,on表示处于安全模式,off表示安全模式已结束
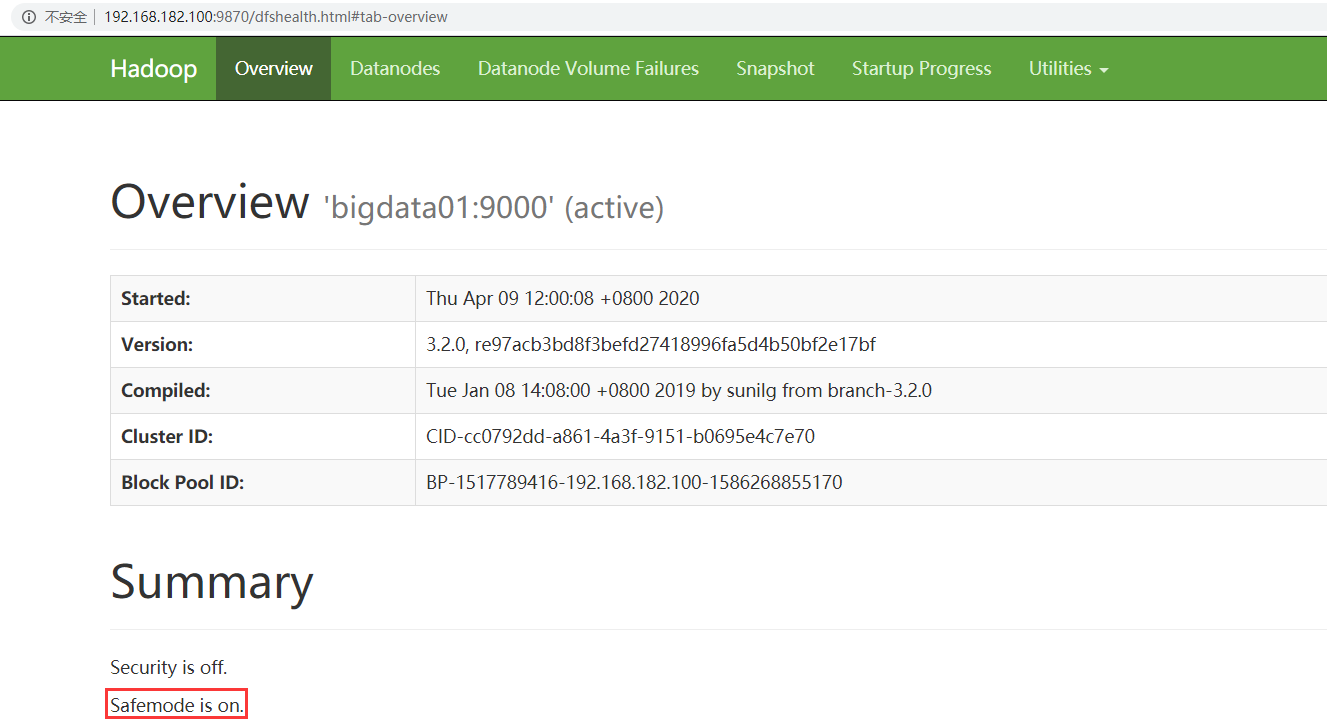
或者通过hdfs命令也可以查看当前的状态
[root@bigdata01 hadoop-3.2.0]# hdfs dfsadmin -safemode get
Safe mode is ON
如果想快速离开安全模式,可以通过命令强制离开,正常情况下建议等HDFS自检完毕,自动退出
[root@bigdata01 hadoop-3.2.0]# hdfs dfsadmin -safemode leave
Safe mode is OFF
此时,再操作HDFS中的文件就可以了。