Hadoop集群安装部署
目录
伪分布集群安装
接下来首先看一下伪分布集群的安装,看一下这张图
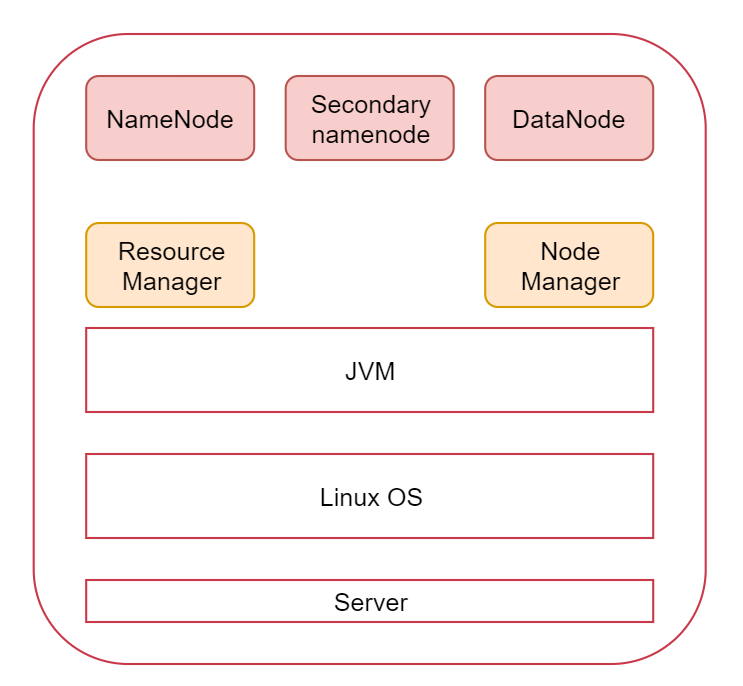
这张图代表是一台Linux机器,也可以称为是一个节点,上面安装的有JDK环境
最上面的是Hadoop集群会启动的进程,其中NameNode、SecondaryNameNode、DataNode是HDFS服务的进程,ResourceManager、NodeManager是YARN服务的进程,MapRedcue在这里没有进程,因为它是一个计算框架,等Hadoop集群安装好了以后MapReduce程序可以在上面执行。
在安装集群之前需要先下载Hadoop的安装包,在这里我们使用hadoop3.2.0这个版本,对应的安装包会发给大家,当然了,也建议大家到官网自己动手下载。
那我们来看一下,在Hadoop官网有一个download按钮,进去之后找到Apache release archive 链接,点击进去就可以找到各种版本的安装包了。
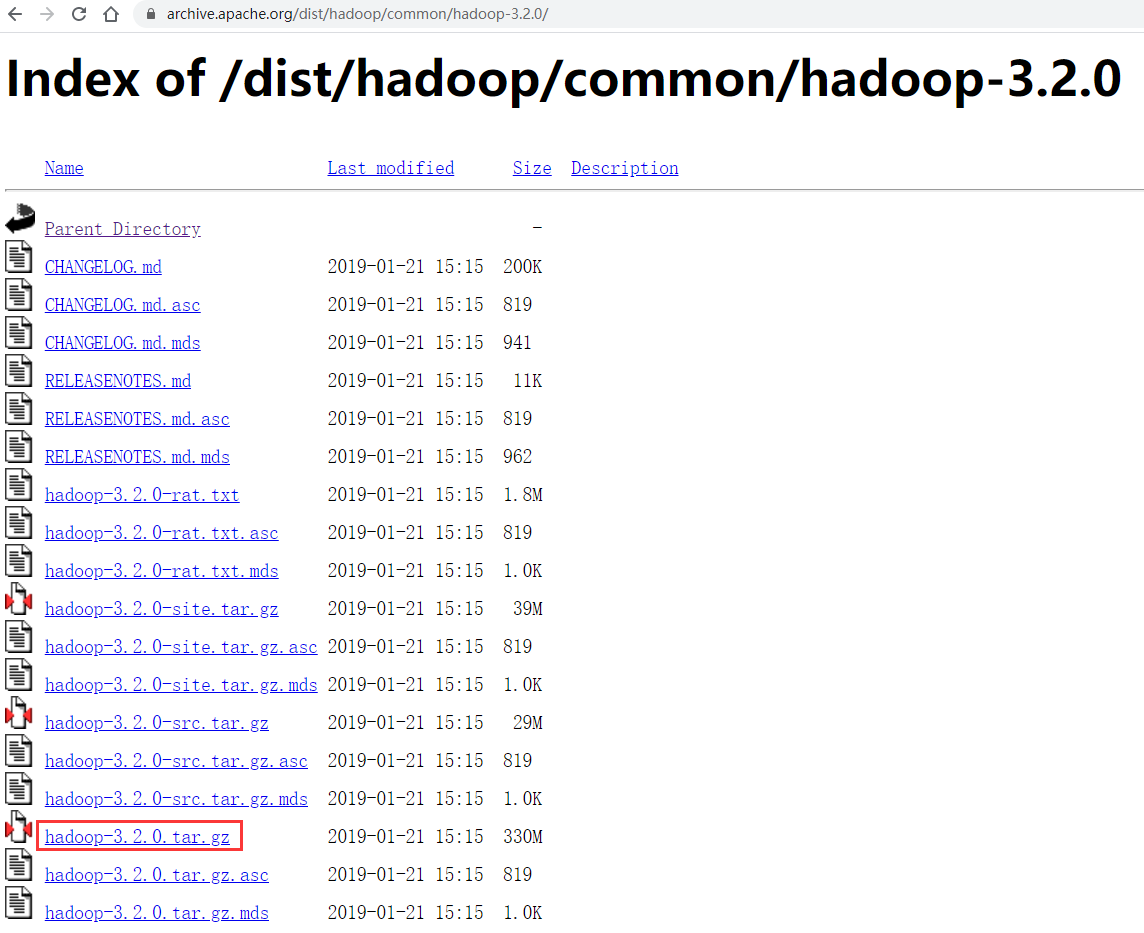
注意:如果发现这个国外的地址下载比较慢,可以使用国内的镜像地址下载,但是这些国内的镜像地址中提供的安装包版本可能不全,如果没有找到我们需要的版本,那还是要老老实实到官网下载。
这些国内的镜像地址里面不仅仅有Hadoop的安装包,里面包含了大部分Apache组织中的软件安装包
安装包百度网盘链接地址获取方式如下:
注意:为了保证下载链接地址一直可用,在这里通过微信公众号【大数据1024】获取,失效的话可以在公众号中随时动态更新。

扫码关注之后回复hadoop即可获取下载地址。
安装包下载好了以后,我们就开始安装伪分布集群了。
在这里使用bigdata01这台机器
首先配置基础环境
ip、hostname、firewalld、ssh免密码登录、JDK
- ip:设置静态ip
[root@bigdata01 ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="static" DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" UUID="9a0df9ec-a85f-40bd-9362-ebe134b7a100" DEVICE="ens33" ONBOOT="yes" IPADDR=192.168.182.100 GATEWAY=192.168.182.2 DNS1=192.168.182.2 [root@bigdata01 ~]# service network restart Restarting network (via systemctl): [ OK ] [root@bigdata01 ~]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:9c:86:11 brd ff:ff:ff:ff:ff:ff inet 192.168.182.100/24 brd 192.168.182.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet6 fe80::c8a8:4edb:db7b:af53/64 scope link noprefixroute valid_lft forever preferred_lft forever - hostname:设置临时主机名和永久主机名
[root@bigdata01 ~]# hostname bigdata01 [root@bigdata01 ~]# vi /etc/hostname bigdata01 firewalld:临时关闭防火墙+永久关闭防火墙
[root@bigdata01 ~]# systemctl stop firewalld [root@bigdata01 ~]# systemctl disable firewalldssh免密码登录
在这需要大致讲解一下ssh的含义,ssh 是secure shell,安全的shell,通过ssh可以远程登录到远程linux机器。
我们下面要讲的hadoop集群就会使用到ssh,我们在启动集群的时候只需要在一台机器上启动就行,然后hadoop会通过ssh连到其它机器,把其它机器上面对应的程序也启动起来。
但是现在有一个问题,就是我们使用ssh连接其它机器的时候会发现需要输入密码,所以现在需要实现ssh免密码登录。
那有同学可能有疑问了,你这里说的多台机器需要配置免密码登录,但是我们现在是伪分布集群啊,只有一台机器
注意了,不管是几台机器的集群,启动集群中程序的步骤都是一样的,都是通过ssh远程连接去操作,就算是一台机器,它也会使用ssh自己连自己,我们现在使用ssh自己连自己也是需要密码的。
[root@bigdata01 ~]# ssh bigdata01
The authenticity of host 'bigdata01 (fe80::c8a8:4edb:db7b:af53%ens33)' can't be established.
ECDSA key fingerprint is SHA256:uUG2QrWRlzXcwfv6GUot9DVs9c+iFugZ7FhR89m2S00.
ECDSA key fingerprint is MD5:82:9d:01:51:06:a7:14:24:a9:16:3d:a1:5e:6d:0d:16.
Are you sure you want to continue connecting (yes/no)? yes【第一次使用这个主机名需要输入yes】
Warning: Permanently added 'bigdata01,fe80::c8a8:4edb:db7b:af53%ens33' (ECDSA) to the list of known hosts.
root@bigdata01's password: 【这里需要输入密码】
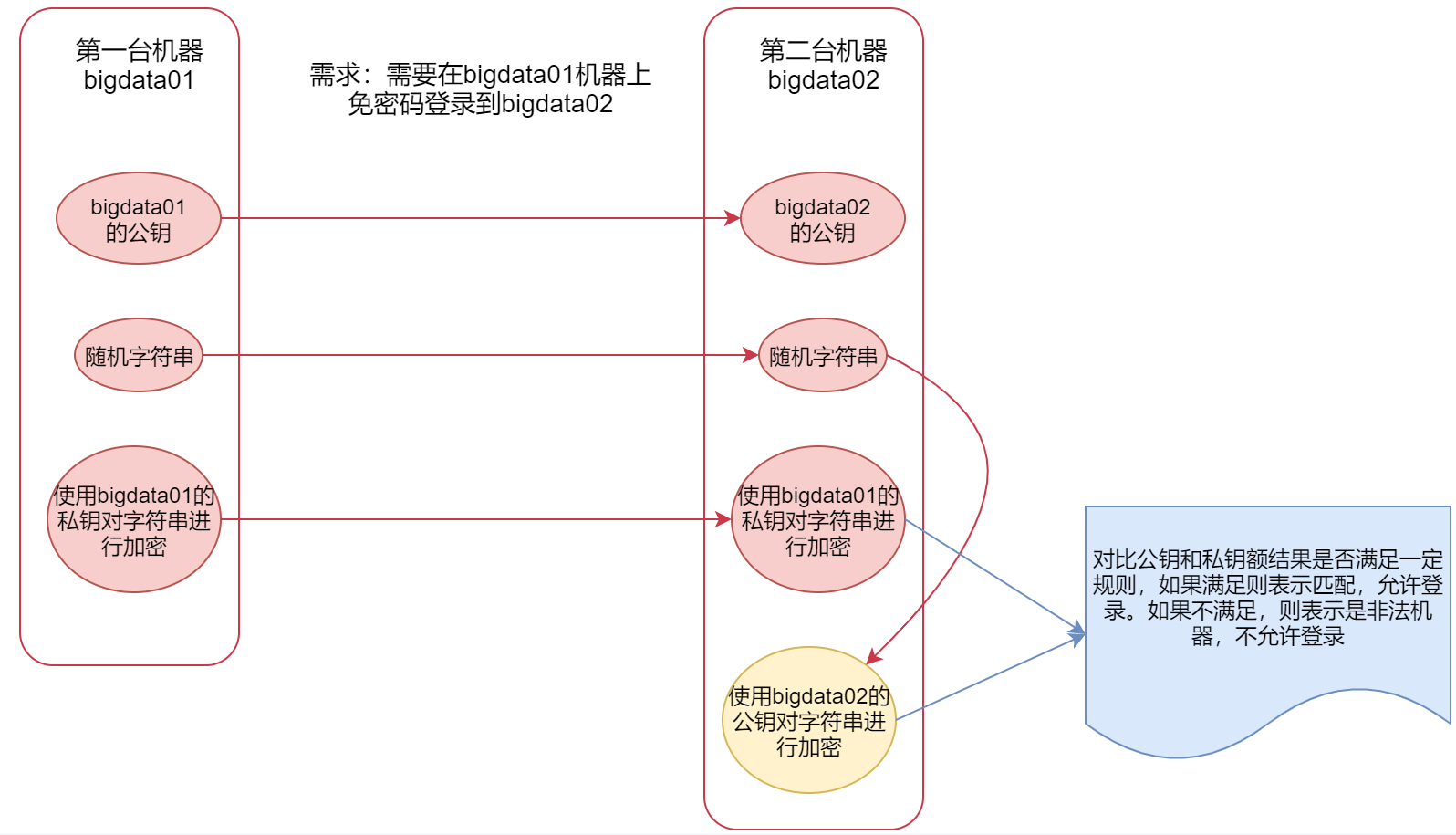
下面详细讲一下ssh免密码登录 ssh这种安全/加密的shell,使用的是非对称加密,加密有两种,对称加密和非对称加密。非对称加密的解密过程是不可逆的,所以这种加密方式比较安全。
非对称加密会产生秘钥,秘钥分为公钥和私钥,在这里公钥是对外公开的,私钥是自己持有的。
那么ssh通信的这个过程是,第一台机器会把自己的公钥给到第二台机器,
当第一台机器要给第二台机器通信的时候,
第一台机器会给第二台机器发送一个随机的字符串,第二台机器会使用公钥对这个字符串加密,
同时第一台机器会使用自己的私钥也对这个字符串进行加密,然后也传给第二台机器
这个时候,第二台机器就有了两份加密的内容,一份是自己使用公钥加密的,一份是第一台机器使用私钥加密传过来的,公钥和私钥是通过一定的算法计算出来的,这个时候,第二台机器就会对比这两份加密之后的内容是否匹配。如果匹配,第二台机器就会认为第一台机器是可信的,就允许登录。如果不相等 就认为是非法的机器。
下面就开始正式配置一下ssh免密码登录,由于我们这里要配置自己免密码登录自己,所以第一台机器和第二台机器都是同一台
首先在bigdata01上执行 ssh-keygen -t rsa
rsa表示的是一种加密算法
注意:执行这个命令以后,需要连续按 4 次回车键回到 linux 命令行才表示这个操作执行 结束,在按回车的时候不需要输入任何内容。
[root@bigdata01 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:I8J8RDun4bklmx9T45SRsKAu7FvP2HqtriYUqUqF1q4 root@bigdata01
The key's randomart image is:
+---[RSA 2048]----+
| o . |
| o o o . |
| o.. = o o |
| +o* o * o |
|..=.= B S = |
|.o.o o B = . |
|o.o . +.o . |
|.E.o.=...o |
| .o+=*.. |
+----[SHA256]-----+
执行以后会在~/.ssh目录下生产对应的公钥和秘钥文件
[root@bigdata01 ~]# ll ~/.ssh/
total 12
-rw-------. 1 root root 1679 Apr 7 16:39 id_rsa
-rw-r--r--. 1 root root 396 Apr 7 16:39 id_rsa.pub
-rw-r--r--. 1 root root 203 Apr 7 16:21 known_hosts
下一步是把公钥拷贝到需要免密码登录的机器上面
[root@bigdata01 ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
然后就可以通过ssh 免密码登录到bigdata01机器了
[root@bigdata01 ~]# ssh bigdata01
Last login: Tue Apr 7 15:05:55 2020 from 192.168.182.1
[root@bigdata01 ~]#
- JDK 下面我们开始安装JDK。
按照正常工作中的开发流程,建议把软件安装包全部都放在/data/soft目录下。
一般公司中正式环境的服务器中都会有一个data盘,负责存储数据,当然也可能会起其他名字
在这里我们没有新挂磁盘,所以手工创建/data/soft目录
[root@bigdata01 ~]# mkdir -p /data/soft
把JDK的安装包上传到/data/soft/目录下
[root@bigdata01 soft]# ll
total 189496
-rw-r--r--. 1 root root 194042837 Apr 6 23:14 jdk-8u202-linux-x64.tar.gz
解压jdk安装包
[root@bigdata01 soft]# tar -zxvf jdk-8u202-linux-x64.tar.gz
重命名jdk
[root@bigdata01 soft]# mv jdk1.8.0_202 jdk1.8
配置环境变量 JAVA_HOME
[root@bigdata01 soft]# vi /etc/profile
.....
export JAVA_HOME=/data/soft/jdk1.8
export PATH=.:$JAVA_HOME/bin:$PATH
验证
[root@bigdata01 soft]# source /etc/profile
[root@bigdata01 soft]# java -version
java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
基础环境搞定了,下面开始安装Hadoop
1:首先把hadoop的安装包上传到/data/soft目录下
[root@bigdata01 soft]# ll
total 527024
-rw-r--r--. 1 root root 345625475 Jul 19 2019 hadoop-3.2.0.tar.gz
drwxr-xr-x. 7 10 143 245 Dec 16 2018 jdk1.8
-rw-r--r--. 1 root root 194042837 Apr 6 23:14 jdk-8u202-linux-x64.tar.gz
2:解压hadoop安装包
[root@bigdata01 soft]# tar -zxvf hadoop-3.2.0.tar.gz
hadoop目录下面有两个重要的目录,一个是bin目录,一个是sbin目录
[root@bigdata01 soft]# cd hadoop-3.2.0
[root@bigdata01 hadoop-3.2.0]# ll
total 184
drwxr-xr-x. 2 1001 1002 203 Jan 8 2019 bin
drwxr-xr-x. 3 1001 1002 20 Jan 8 2019 etc
drwxr-xr-x. 2 1001 1002 106 Jan 8 2019 include
drwxr-xr-x. 3 1001 1002 20 Jan 8 2019 lib
drwxr-xr-x. 4 1001 1002 4096 Jan 8 2019 libexec
-rw-rw-r--. 1 1001 1002 150569 Oct 19 2018 LICENSE.txt
-rw-rw-r--. 1 1001 1002 22125 Oct 19 2018 NOTICE.txt
-rw-rw-r--. 1 1001 1002 1361 Oct 19 2018 README.txt
drwxr-xr-x. 3 1001 1002 4096 Jan 8 2019 sbin
drwxr-xr-x. 4 1001 1002 31 Jan 8 2019 share
我们看一下bin目录,这里面有hdfs,yarn等脚本,这些脚本后期主要是为了操作hadoop集群中的hdfs和yarn组件的
再来看一下sbin目录,这里面有很多start stop开头的脚本,这些脚本是负责启动 或者停止集群中的组件的。
其实还有一个重要的目录是etc/hadoop目录,这个目录里面的文件主要是hadoop的一些配置文件,还是比较重要的。一会我们安装hadoop,主要就是需要修改这个目录下面的文件。
因为我们会用到bin目录和sbin目录下面的一些脚本,为了方便使用,我们需要配置一下环境变量。
[root@bigdata01 hadoop-3.2.0]# vi /etc/profile
.......
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_HOME=/data/soft/hadoop-3.2.0
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
[root@bigdata01 hadoop-3.2.0]# source /etc/profile
3:修改Hadoop相关配置文件
进入配置文件所在目录
[root@bigdata01 hadoop-3.2.0]# cd etc/hadoop/
[root@bigdata01 hadoop]#
主要修改下面这几个文件:
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml workers
首先修改 hadoop-env.sh 文件,增加环境变量信息,添加到hadoop-env.sh 文件末尾即可。
JAVA_HOME:指定java的安装位置
HADOOP_LOG_DIR:hadoop的日志的存放目录
[root@bigdata01 hadoop]# vi hadoop-env.sh
.......
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
修改 core-site.xml 文件
注意 fs.defaultFS 属性中的主机名需要和你配置的主机名保持一致
[root@bigdata01 hadoop]# vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_repo</value>
</property>
</configuration>
修改hdfs-site.xml文件,把hdfs中文件副本的数量设置为1,因为现在伪分布集群只有一个节点
[root@bigdata01 hadoop]# vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
修改mapred-site.xml,设置mapreduce使用的资源调度框架
[root@bigdata01 hadoop]# vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml,设置yarn上支持运行的服务和环境变量白名单
[root@bigdata01 hadoop]# vi yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
修改workers,设置集群中从节点的主机名信息,在这里就一台集群,所以就填写bigdata01即可
[root@bigdata01 hadoop]# vi workers
bigdata01
配置文件到这就修改好了,但是还不能直接启动,因为Hadoop中的HDFS是一个分布式的文件系统,文件系统在使用之前是需要先格式化的,就类似我们买一块新的磁盘,在安装系统之前需要先格式化才可以使用。
4:格式化HDFS
[root@bigdata01 hadoop]# cd /data/soft/hadoop-3.2.0
[root@bigdata01 hadoop-3.2.0]# bin/hdfs namenode -format
WARNING: /data/hadoop_repo/logs/hadoop does not exist. Creating.
2020-04-07 17:45:22,086 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = bigdata01/192.168.182.100
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.2.0
STARTUP_MSG: classpath = ...
STARTUP_MSG: build = https://github.com/apache/hadoop.git -r e97acb3bd8f3befd27418996fa5d4b50bf2e17bf; compiled by 'sunilg' on 2019-01-08T06:08Z
STARTUP_MSG: java = 1.8.0_202
************************************************************/
2020-04-07 17:45:22,194 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
2020-04-07 17:45:22,411 INFO namenode.NameNode: createNameNode [-format]
Formatting using clusterid: CID-8f0078dd-d80d-4c83-9d21-21dbbac6127d
2020-04-07 17:45:24,084 INFO namenode.FSEditLog: Edit logging is async:true
2020-04-07 17:45:24,102 INFO namenode.FSNamesystem: KeyProvider: null
2020-04-07 17:45:24,103 INFO namenode.FSNamesystem: fsLock is fair: true
2020-04-07 17:45:24,104 INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false
2020-04-07 17:45:24,177 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE)
2020-04-07 17:45:24,177 INFO namenode.FSNamesystem: supergroup = supergroup
2020-04-07 17:45:24,177 INFO namenode.FSNamesystem: isPermissionEnabled = true
2020-04-07 17:45:24,177 INFO namenode.FSNamesystem: HA Enabled: false
2020-04-07 17:45:24,246 INFO common.Util: dfs.datanode.fileio.profiling.sampling.percentage set to 0. Disabling file IO profiling
2020-04-07 17:45:24,260 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit: configured=1000, counted=60, effected=1000
2020-04-07 17:45:24,260 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
2020-04-07 17:45:24,272 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
2020-04-07 17:45:24,307 INFO blockmanagement.BlockManager: The block deletion will start around 2020 Apr 07 17:45:24
2020-04-07 17:45:24,309 INFO util.GSet: Computing capacity for map BlocksMap
2020-04-07 17:45:24,310 INFO util.GSet: VM type = 64-bit
2020-04-07 17:45:24,333 INFO util.GSet: 2.0% max memory 440.8 MB = 8.8 MB
2020-04-07 17:45:24,333 INFO util.GSet: capacity = 2^20 = 1048576 entries
2020-04-07 17:45:24,341 INFO blockmanagement.BlockManager: Storage policy satisfier is disabled
2020-04-07 17:45:24,341 INFO blockmanagement.BlockManager: dfs.block.access.token.enable = false
2020-04-07 17:45:24,348 INFO Configuration.deprecation: No unit for dfs.namenode.safemode.extension(30000) assuming MILLISECONDS
2020-04-07 17:45:24,348 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
2020-04-07 17:45:24,348 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.min.datanodes = 0
2020-04-07 17:45:24,348 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.extension = 30000
2020-04-07 17:45:24,348 INFO blockmanagement.BlockManager: defaultReplication = 1
2020-04-07 17:45:24,348 INFO blockmanagement.BlockManager: maxReplication = 512
2020-04-07 17:45:24,348 INFO blockmanagement.BlockManager: minReplication = 1
2020-04-07 17:45:24,348 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
2020-04-07 17:45:24,348 INFO blockmanagement.BlockManager: redundancyRecheckInterval = 3000ms
2020-04-07 17:45:24,348 INFO blockmanagement.BlockManager: encryptDataTransfer = false
2020-04-07 17:45:24,348 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
2020-04-07 17:45:24,526 INFO namenode.FSDirectory: GLOBAL serial map: bits=29 maxEntries=536870911
2020-04-07 17:45:24,526 INFO namenode.FSDirectory: USER serial map: bits=24 maxEntries=16777215
2020-04-07 17:45:24,526 INFO namenode.FSDirectory: GROUP serial map: bits=24 maxEntries=16777215
2020-04-07 17:45:24,526 INFO namenode.FSDirectory: XATTR serial map: bits=24 maxEntries=16777215
2020-04-07 17:45:24,538 INFO util.GSet: Computing capacity for map INodeMap
2020-04-07 17:45:24,538 INFO util.GSet: VM type = 64-bit
2020-04-07 17:45:24,539 INFO util.GSet: 1.0% max memory 440.8 MB = 4.4 MB
2020-04-07 17:45:24,539 INFO util.GSet: capacity = 2^19 = 524288 entries
2020-04-07 17:45:24,539 INFO namenode.FSDirectory: ACLs enabled? false
2020-04-07 17:45:24,539 INFO namenode.FSDirectory: POSIX ACL inheritance enabled? true
2020-04-07 17:45:24,539 INFO namenode.FSDirectory: XAttrs enabled? true
2020-04-07 17:45:24,539 INFO namenode.NameNode: Caching file names occurring more than 10 times
2020-04-07 17:45:24,545 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: false, skipCaptureAccessTimeOnlyChange: false, snapshotDiffAllowSnapRootDescendant: true, maxSnapshotLimit: 65536
2020-04-07 17:45:24,549 INFO snapshot.SnapshotManager: SkipList is disabled
2020-04-07 17:45:24,552 INFO util.GSet: Computing capacity for map cachedBlocks
2020-04-07 17:45:24,552 INFO util.GSet: VM type = 64-bit
2020-04-07 17:45:24,552 INFO util.GSet: 0.25% max memory 440.8 MB = 1.1 MB
2020-04-07 17:45:24,552 INFO util.GSet: capacity = 2^17 = 131072 entries
2020-04-07 17:45:24,558 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
2020-04-07 17:45:24,558 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
2020-04-07 17:45:24,558 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
2020-04-07 17:45:24,565 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
2020-04-07 17:45:24,565 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
2020-04-07 17:45:24,567 INFO util.GSet: Computing capacity for map NameNodeRetryCache
2020-04-07 17:45:24,567 INFO util.GSet: VM type = 64-bit
2020-04-07 17:45:24,567 INFO util.GSet: 0.029999999329447746% max memory 440.8 MB = 135.4 KB
2020-04-07 17:45:24,567 INFO util.GSet: capacity = 2^14 = 16384 entries
2020-04-07 17:45:24,665 INFO namenode.FSImage: Allocated new BlockPoolId: BP-712712880-192.168.182.100-1586252724657
2020-04-07 17:45:24,689 INFO common.Storage: Storage directory /data/hadoop_repo/dfs/name has been successfully formatted.
2020-04-07 17:45:24,699 INFO namenode.FSImageFormatProtobuf: Saving image file /data/hadoop_repo/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2020-04-07 17:45:24,831 INFO namenode.FSImageFormatProtobuf: Image file /data/hadoop_repo/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 396 bytes saved in 0 seconds .
2020-04-07 17:45:24,842 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2020-04-07 17:45:24,848 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at bigdata01/192.168.182.100
************************************************************/
如果能看到successfully formatted这条信息就说明格式化成功了。
如果提示错误,一般都是因为配置文件的问题,当然需要根据具体的报错信息去分析问题。
注意:格式化操作只能执行一次,如果格式化的时候失败了,可以修改配置文件后再执行格式化,如果格式化成功了就不能再重复执行了,否则集群就会出现问题。
如果确实需要重复执行,那么需要把/data/hadoop_repo目录中的内容全部删除,再执行格式化
可以这样理解,我们买一块新磁盘回来装操作系统,第一次使用之前会格式化一下,后面你会没事就去格式化一下吗?肯定不会的,格式化之后操作系统又得重装了。
5:启动伪分布集群
使用sbin目录下的start-all.sh脚本
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
Starting namenodes on [bigdata01]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [bigdata01]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
执行的时候发现有很多ERROR信息,提示缺少HDFS和YARN的一些用户信息。
解决方案如下:
修改sbin目录下的start-dfs.sh,stop-dfs.sh这两个脚本文件,在文件前面增加如下内容
[root@bigdata01 hadoop-3.2.0]# cd sbin/
[root@bigdata01 sbin]# vi start-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
[root@bigdata01 sbin]# vi stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
修改sbin目录下的start-yarn.sh,stop-yarn.sh这两个脚本文件,在文件前面增加如下内容
[root@bigdata01 sbin]# vi start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
[root@bigdata01 sbin]# vi stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
再启动集群
[root@bigdata01 sbin]# cd /data/soft/hadoop-3.2.0
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
Starting namenodes on [bigdata01]
Last login: Tue Apr 7 16:45:28 CST 2020 from fe80::c8a8:4edb:db7b:af53%ens33 on pts/1
Starting datanodes
Last login: Tue Apr 7 17:59:21 CST 2020 on pts/0
Starting secondary namenodes [bigdata01]
Last login: Tue Apr 7 17:59:23 CST 2020 on pts/0
Starting resourcemanager
Last login: Tue Apr 7 17:59:30 CST 2020 on pts/0
Starting nodemanagers
Last login: Tue Apr 7 17:59:37 CST 2020 on pts/0
6:验证集群进程信息
执行jps命令可以查看集群的进程信息,去掉Jps这个进程之外还需要有5个进程才说明集群是正常启动的
[root@bigdata01 hadoop-3.2.0]# jps
3267 NameNode
3859 ResourceManager
3397 DataNode
3623 SecondaryNameNode
3996 NodeManager
4319 Jps
还可以通过webui界面来验证集群服务是否正常
- HDFS webui界面:http://192.168.182.100:9870
- YARN webui界面:http://192.168.182.100:8088
如果想通过主机名访问,则需要修改windows机器中的hosts文件
文件所在位置为:C:\Windows\System32\drivers\etc\HOSTS
在文件中增加下面内容,这个其实就是Linux虚拟机的ip和主机名,在这里做一个映射之后,就可以在Windows机器中通过主机名访问这个Linux虚拟机了。
192.168.182.100 bigdata01
注意:如果遇到这个文件无法修改,一般是由于权限问题,在打开的时候可以选择使用管理员模式打开。
7:停止集群
如果修改了集群的配置文件或者是其它原因要停止集群,可以使用下面命令
[root@bigdata01 hadoop-3.2.0]# sbin/stop-all.sh
Stopping namenodes on [bigdata01]
Last login: Tue Apr 7 17:59:40 CST 2020 on pts/0
Stopping datanodes
Last login: Tue Apr 7 18:06:09 CST 2020 on pts/0
Stopping secondary namenodes [bigdata01]
Last login: Tue Apr 7 18:06:10 CST 2020 on pts/0
Stopping nodemanagers
Last login: Tue Apr 7 18:06:13 CST 2020 on pts/0
Stopping resourcemanager
Last login: Tue Apr 7 18:06:16 CST 2020 on pts/0
分布式集群安装
伪分布集群搞定了以后我们来看一下真正的分布式集群是什么样的
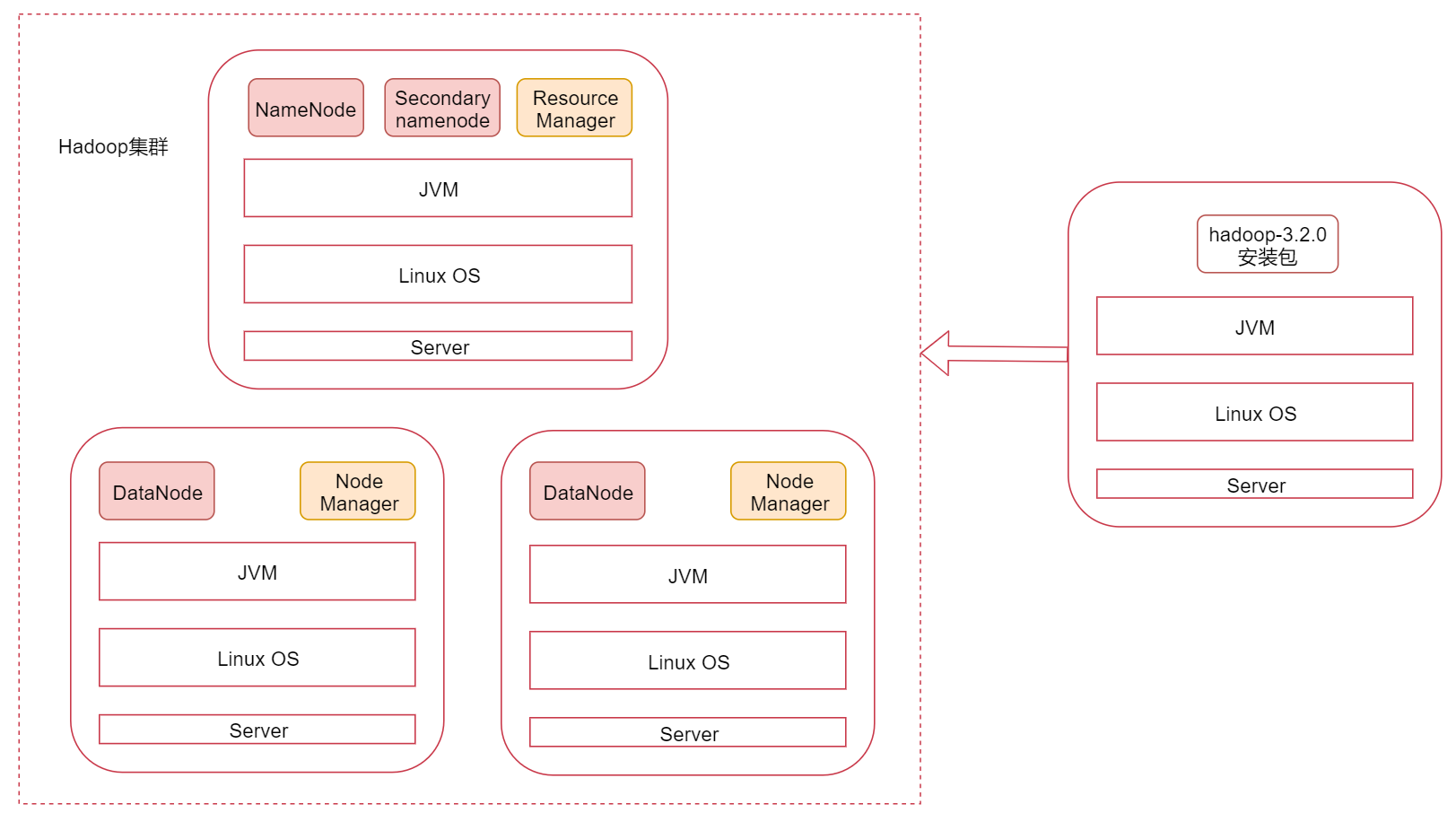
看一下这张图,图里面表示是三个节点,左边这一个是主节点,右边的两个是从节点,hadoop集群是支持主从架构的。
不同节点上面启动的进程默认是不一样的。
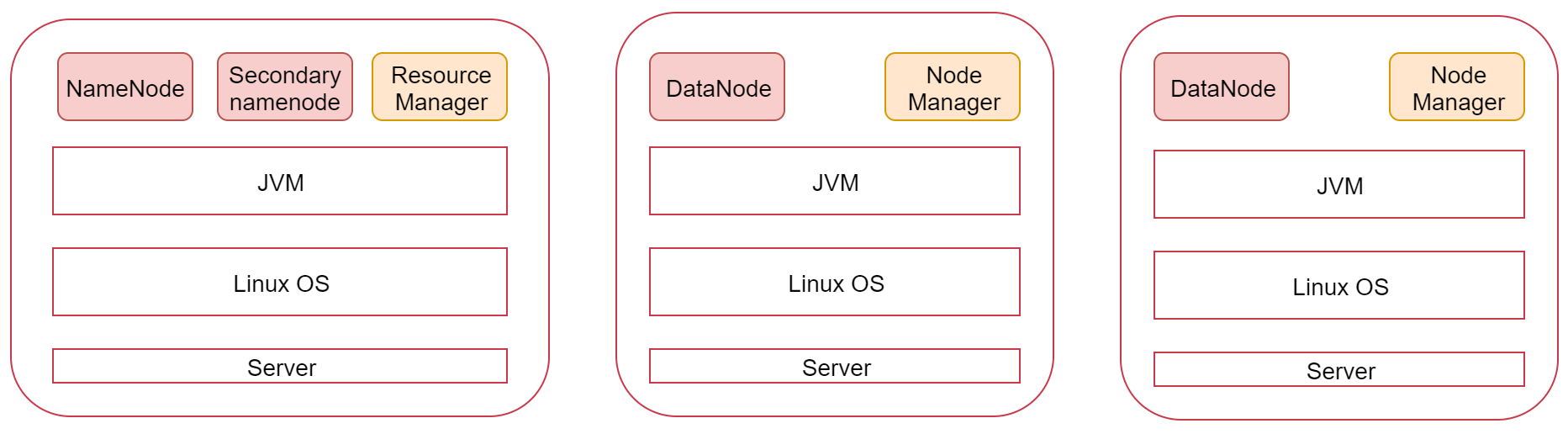
下面我们就根据图中的规划实现一个一主两从的hadoop集群
环境准备:三个节点
bigdata01 192.168.182.100
bigdata02 192.168.182.101
bigdata03 192.168.182.102
注意:每个节点的基础环境都要先配置好,先把ip、hostname、firewalld、ssh免密码登录、JDK这些基础环境配置好
目前的节点数量是不够的,按照第一周学习的内容,通过克隆的方式创建多个节点,具体克隆的步骤在这就不再赘述了。
先把bigdata01中之前按照的hadoop删掉,删除解压的目录,修改环境变量即可。
注意:我们需要把bigdata01节点中/data目录下的hadoop_repo目录和/data/soft下的hadoop-3.2.0目录删掉,恢复此节点的环境,这里面记录的有之前伪分布集群的一些信息。
[root@bigdata01 ~]# rm -rf /data/soft/hadoop-3.2.0
[root@bigdata01 ~]# rm -rf /data/hadoop_repo
假设我们现在已经具备三台linux机器了,里面都是全新的环境。
下面开始操作。
注意:针对这三台机器的ip、hostname、firewalld、JDK这些基础环境的配置步骤在这里就不再记录了,具体步骤参考2.1中的步骤。
bigdata01
bigdata02
bigdata03
这三台机器的ip、hostname、firewalld、ssh免密码登录、JDK这些基础环境已经配置ok。
这些基础环境配置好以后还没完,还有一些配置需要完善。
- 配置/etc/hosts
因为需要在主节点远程连接两个从节点,所以需要让主节点能够识别从节点的主机名,使用主机名远程访问,默认情况下只能使用ip远程访问,想要使用主机名远程访问的话需要在节点的/etc/hosts文件中配置对应机器的ip和主机名信息。
所以在这里我们就需要在bigdata01的/etc/hosts文件中配置下面信息,最好把当前节点信息也配置到里面,这样这个文件中的内容就通用了,可以直接拷贝到另外两个从节点
[root@bigdata01 ~]# vi /etc/hosts
192.168.182.100 bigdata01
192.168.182.101 bigdata02
192.168.182.102 bigdata03
修改bigdata02的/etc/hosts文件
[root@bigdata02 ~]# vi /etc/hosts
192.168.182.100 bigdata01
192.168.182.101 bigdata02
192.168.182.102 bigdata03
修改bigdata03的/etc/hosts文件
[root@bigdata03 ~]# vi /etc/hosts
192.168.182.100 bigdata01
192.168.182.101 bigdata02
192.168.182.102 bigdata03
- 集群节点之间时间同步
集群只要涉及到多个节点的就需要对这些节点做时间同步,如果节点之间时间不同步相差太多,会应该集群的稳定性,甚至导致集群出问题。
首先在bigdata01节点上操作
使用ntpdate -u ntp.sjtu.edu.cn实现时间同步,但是执行的时候提示找不到ntpdata命令
[root@bigdata01 ~]# ntpdate -u ntp.sjtu.edu.cn
-bash: ntpdate: command not found
默认是没有ntpdate命令的,需要使用yum在线安装,执行命令 yum install -y ntpdate
[root@bigdata01 ~]# yum install -y ntpdate
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: mirrors.cn99.com
* extras: mirrors.cn99.com
* updates: mirrors.cn99.com
base | 3.6 kB 00:00
extras | 2.9 kB 00:00
updates | 2.9 kB 00:00
Resolving Dependencies
--> Running transaction check
---> Package ntpdate.x86_64 0:4.2.6p5-29.el7.centos will be installed
--> Finished Dependency Resolution
Dependencies Resolved
===============================================================================
Package Arch Version Repository Size
===============================================================================
Installing:
ntpdate x86_64 4.2.6p5-29.el7.centos base 86 k
Transaction Summary
===============================================================================
Install 1 Package
Total download size: 86 k
Installed size: 121 k
Downloading packages:
ntpdate-4.2.6p5-29.el7.centos.x86_64.rpm | 86 kB 00:00
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Installing : ntpdate-4.2.6p5-29.el7.centos.x86_64 1/1
Verifying : ntpdate-4.2.6p5-29.el7.centos.x86_64 1/1
Installed:
ntpdate.x86_64 0:4.2.6p5-29.el7.centos
Complete!
然后手动执行ntpdate -u ntp.sjtu.edu.cn 确认是否可以正常执行
[root@bigdata01 ~]# ntpdate -u ntp.sjtu.edu.cn
7 Apr 21:21:01 ntpdate[5447]: step time server 185.255.55.20 offset 6.252298 sec
建议把这个同步时间的操作添加到linux的crontab定时器中,每分钟执行一次
[root@bigdata01 ~]# vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn
然后在bigdata02和bigdata03节点上配置时间同步
在bigdata02节点上操作
[root@bigdata02 ~]# yum install -y ntpdate
[root@bigdata02 ~]# vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn
在bigdata03节点上操作
[root@bigdata03 ~]# yum install -y ntpdate
[root@bigdata03 ~]# vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn
- SSH免密码登录完善
注意:针对免密码登录,目前只实现了自己免密码登录自己,最终需要实现主机点可以免密码登录到所有节点,所以还需要完善免密码登录操作。
首先在bigdata01机器上执行下面命令,将公钥信息拷贝到两个从节点
[root@bigdata01 ~]# scp ~/.ssh/authorized_keys bigdata02:~/
The authenticity of host 'bigdata02 (192.168.182.101)' can't be established.
ECDSA key fingerprint is SHA256:uUG2QrWRlzXcwfv6GUot9DVs9c+iFugZ7FhR89m2S00.
ECDSA key fingerprint is MD5:82:9d:01:51:06:a7:14:24:a9:16:3d:a1:5e:6d:0d:16.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'bigdata02,192.168.182.101' (ECDSA) to the list of known hosts.
root@bigdata02's password:
authorized_keys 100% 396 506.3KB/s 00:00
[root@bigdata01 ~]# scp ~/.ssh/authorized_keys bigdata03:~/
The authenticity of host 'bigdata03 (192.168.182.102)' can't be established.
ECDSA key fingerprint is SHA256:uUG2QrWRlzXcwfv6GUot9DVs9c+iFugZ7FhR89m2S00.
ECDSA key fingerprint is MD5:82:9d:01:51:06:a7:14:24:a9:16:3d:a1:5e:6d:0d:16.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'bigdata03,192.168.182.102' (ECDSA) to the list of known hosts.
root@bigdata03's password:
authorized_keys 100% 396 606.1KB/s 00:00
然后在bigdata02和bigdata03上执行
bigdata02:
[root@bigdata02 ~]# cat ~/authorized_keys >> ~/.ssh/authorized_keys
bigdata03:
[root@bigdata03 ~]# cat ~/authorized_keys >> ~/.ssh/authorized_keys
验证一下效果,在bigdata01节点上使用ssh远程连接两个从节点,如果不需要输入密码就表示是成功的,此时主机点可以免密码登录到所有节点。
[root@bigdata01 ~]# ssh bigdata02
Last login: Tue Apr 7 21:33:58 2020 from bigdata01
[root@bigdata02 ~]# exit
logout
Connection to bigdata02 closed.
[root@bigdata01 ~]# ssh bigdata03
Last login: Tue Apr 7 21:17:30 2020 from 192.168.182.1
[root@bigdata03 ~]# exit
logout
Connection to bigdata03 closed.
[root@bigdata01 ~]#
有没有必要实现从节点之间互相免密码登录呢?
这个就没有必要了,因为在启动集群的时候只有主节点需要远程连接其它节点。
OK,那到这为止,集群中三个节点的基础环境就都配置完毕了,接下来就需要在这三个节点中安装Hadoop了。
首先在bigdata01节点上安装。
1:把hadoop-3.2.0.tar.gz安装包上传到linux机器的/data/soft目录下
[root@bigdata01 soft]# ll
total 527024
-rw-r--r--. 1 root root 345625475 Jul 19 2019 hadoop-3.2.0.tar.gz
drwxr-xr-x. 7 10 143 245 Dec 16 2018 jdk1.8
-rw-r--r--. 1 root root 194042837 Apr 6 23:14 jdk-8u202-linux-x64.tar.gz
2:解压hadoop安装包
[root@bigdata01 soft]# tar -zxvf hadoop-3.2.0.tar.gz
3:修改hadoop相关配置文件
进入配置文件所在目录
[root@bigdata01 soft]# cd hadoop-3.2.0/etc/hadoop/
[root@bigdata01 hadoop]#
首先修改hadoop-env.sh文件,在文件末尾增加环境变量信息
[root@bigdata01 hadoop]# vi hadoop-env.sh
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
修改core-site.xml文件,注意fs.defaultFS属性中的主机名需要和主节点的主机名保持一致
[root@bigdata01 hadoop]# vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_repo</value>
</property>
</configuration>
修改hdfs-site.xml文件,把hdfs中文件副本的数量设置为2,最多为2,因为现在集群中有两个从节点,还有secondaryNamenode进程所在的节点信息
[root@bigdata01 hadoop]# vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:50090</value>
</property>
</configuration>
修改mapred-site.xml,设置mapreduce使用的资源调度框架
[root@bigdata01 hadoop]# vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml,设置yarn上支持运行的服务和环境变量白名单
注意,针对分布式集群在这个配置文件中还需要设置resourcemanager的hostname,否则nodemanager找不到resourcemanager节点。
[root@bigdata01 hadoop]# vi yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata01</value>
</property>
</configuration>
修改workers文件,增加所有从节点的主机名,一个一行
[root@bigdata01 hadoop]# vi workers
bigdata02
bigdata03
修改启动脚本
修改start-dfs.sh,stop-dfs.sh这两个脚本文件,在文件前面增加如下内容
[root@bigdata01 hadoop]# cd /data/soft/hadoop-3.2.0/sbin
[root@bigdata01 sbin]# vi start-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
[root@bigdata01 sbin]# vi stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
修改start-yarn.sh,stop-yarn.sh这两个脚本文件,在文件前面增加如下内容
[root@bigdata01 sbin]# vi start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
[root@bigdata01 sbin]# vi stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
4:把bigdata01节点上将修改好配置的安装包拷贝到其他两个从节点
[root@bigdata01 sbin]# cd /data/soft/
[root@bigdata01 soft]# scp -rq hadoop-3.2.0 bigdata02:/data/soft/
[root@bigdata01 soft]# scp -rq hadoop-3.2.0 bigdata03:/data/soft/
5:在bigdata01节点上格式化HDFS
[root@bigdata01 soft]# cd /data/soft/hadoop-3.2.0
[root@bigdata01 hadoop-3.2.0]# bin/hdfs namenode -format
如果在后面的日志信息中能看到这一行,则说明namenode格式化成功。
common.Storage: Storage directory /data/hadoop_repo/dfs/name has been successfully formatted.
6:启动集群,在bigdata01节点上执行下面命令
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
Starting namenodes on [bigdata01]
Last login: Tue Apr 7 21:03:21 CST 2020 from 192.168.182.1 on pts/2
Starting datanodes
Last login: Tue Apr 7 22:15:51 CST 2020 on pts/1
bigdata02: WARNING: /data/hadoop_repo/logs/hadoop does not exist. Creating.
bigdata03: WARNING: /data/hadoop_repo/logs/hadoop does not exist. Creating.
Starting secondary namenodes [bigdata01]
Last login: Tue Apr 7 22:15:53 CST 2020 on pts/1
Starting resourcemanager
Last login: Tue Apr 7 22:15:58 CST 2020 on pts/1
Starting nodemanagers
Last login: Tue Apr 7 22:16:04 CST 2020 on pts/1
7:验证集群
分别在3台机器上执行jps命令,进程信息如下所示:
在bigdata01节点执行
[root@bigdata01 hadoop-3.2.0]# jps
6128 NameNode
6621 ResourceManager
6382 SecondaryNameNode
在bigdata02节点执行
[root@bigdata02 ~]# jps
2385 NodeManager
2276 DataNode
在bigdata03节点执行
[root@bigdata03 ~]# jps
2326 NodeManager
2217 DataNode
8:停止集群
在bigdata01节点上执行停止命令
[root@bigdata01 hadoop-3.2.0]# sbin/stop-all.sh
Stopping namenodes on [bigdata01]
Last login: Tue Apr 7 22:21:16 CST 2020 on pts/1
Stopping datanodes
Last login: Tue Apr 7 22:22:42 CST 2020 on pts/1
Stopping secondary namenodes [bigdata01]
Last login: Tue Apr 7 22:22:44 CST 2020 on pts/1
Stopping nodemanagers
Last login: Tue Apr 7 22:22:46 CST 2020 on pts/1
Stopping resourcemanager
Last login: Tue Apr 7 22:22:50 CST 2020 on pts/1
至此,hadoop分布式集群安装成功!
注意:前面这些操作步骤这么多,如果我是新手我怎么知道需要做这些操作呢?不用担心,官方给提供的有使用说明,也就是我们平时所说的官方文档,我们平时买各种各样的东西都是有说明书的,上面会告诉你该怎么使用,这个是最权威最准确的。
那我们来看一下Hadoop的官网文档: https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
Hadoop的客户端节点
在实际工作中不建议直接连接集群中的节点来操作集群,直接把集群中的节点暴露给普通开发人员是不安全的
建议在业务机器上安装Hadoop,只需要保证业务机器上的Hadoop的配置和集群中的配置保持一致即可,这样就可以在业务机器上操作Hadoop集群了,此机器就称为是Hadoop的客户端节点
Hadoop的客户端节点可能会有多个,理论上是我们想要在哪台机器上操作hadoop集群就可以把这台机器配置为hadoop集群的客户端节点。