快速了解Hadoop
目录
什么是Hadoop
我们生活在一个数据大爆炸的时代,数据飞快的增长,急需解决海量数据的存储和计算问题。
这个时候,Hadoop就应运而生了。
Hadoop是一个适合海量数据的分布式存储和分布式计算的框架。
在这里要注意,分布式存储和分布式计算。
分布式存储,可以简单理解为存储数据的时候,数据不只存在一台机器上面,它会存在多台机器上面。
分布式计算简单理解,就是由很多台机器并行处理数据,咱们在写java程序的时候,写的一般都是单机的程序,只在一台机器上运行,这样程序的处理能力是有限的。
在这里先这样理解就可以,后面我们会详细分析。
Hadoop的作者是Doug Cutting,他在给这个框架起名字的时候是很偶然的,作者的孩子有一个毛绒象玩具,他孩子总是对着这个玩具叫 Hadoop、Hadoop、所以,作者就以此来命名了。
当大家以后也达到这种高度的时候,你在实现一个框架的时候用自己的名字来命名都是可以的,这样就很炫酷了。
Hadoop发行版介绍
接下来看一下Hadoop的发行版,什么叫发行版呢?
举一个大家接触比较多的例子,
目前手机操作系统有两大阵营,一个是苹果的IOS,还有一个是谷歌的Android
IOS是闭源的,也就不存在多个发行版了,如果你基于IOS改造一下,弄一个新的手机系统出来,会被苹果告破产的。所以IOS是没有其它发行版的,只有官方这一个版本。
Android是开源的,所以基于这个系统,很多手机厂商都会对它进行封装改造,因为这些手机厂商会感觉原生的Android系统的界面看起来比较low,或者某一些功能不太适合中国人的使用习惯,所以他们就会进行改造,例如国内的魅族、小米、锤子这些手机厂商都基于Android打造了自己的手机操作系统,那这些就是Android系统的一些发行版。
那针对Hadoop也是一样的,目前Hadoop已经演变为大数据的代名词,形成了一套完善的大数据生态系统,并且Hadoop是Apache开源的,它的开源协议决定了任何人都可以对其进行修改,并作为开源或者商业版进行发布/销售。
所以目前Hadoop发行版非常的多,有华为发行版、Intel发行版、Cloudera发行版CDH、Hortonworks发行版HDP,这些发行版都是基于Apache Hadoop衍生出来的。
在这里我们挑几个重点的分析一下:
首先是官方原生版本:Apache Hadoop
Apache是一个IT领域的公益组织,类似于红十字会,Apache这个组织里面的软件都是开源的,大家可以随便使用,随便修改,我们后面学习的99%的大数据技术框架都是Apache开源的,所以在这里我们会学习原生的Hadoop,只要掌握了原生Hadoop使用,后期想要操作其它发行版的Hadoop也是很简单的,其它发行版都是会兼容原生Hadoop的,这一点大家不同担心。 原生Hadoop的缺点是没有技术支持,遇到问题需要自己解决,或者通过官网的社区提问,但是回复一般比较慢,也不保证能解决问题, 还有一点就是原生Hadoop搭建集群的时候比较麻烦,需要修改很多配置文件,如果集群机器过多的话,针对运维人员的压力是比较大的,这块等后面我们自己在搭建集群的时候大家就可以感受到了。
那接着往下面看 Cloudera Hadoop(CDH)
注意了,CDH是一个商业版本,它对官方版本做了一些优化,提供收费技术支持,提供界面操作,方便集群运维管理 CDH目前在企业中使用的还是比较多的,虽然CDH是收费的,但是CDH中的一些基本功能是不收费的,可以一直使用,高级功能是需要收费才能使用的,如果不想付费,也能凑合着使用。
还有一个比较常用的是HortonWorks(HDP)
它呢,是开源的,也提供的有界面操作,方便运维管理,一般互联网公司偏向于使用这个
注意了,再爆一个料,最新消息,目前HDP已经被CDH收购,都是属于一个公司的产品,后期HDP是否会合并到CDH中,还不得而知,具体还要看这个公司的运营策略了。
最终的建议:建议在实际工作中搭建大数据平台时选择 CDH或者HDP,方便运维管理,要不然,管理上千台机器的原生Hadoop集群,运维同学是会哭的。
注意了,学习过程中我们使用原生Hadoop,在最后我们会讲一下CDH和HDP的使用
Hadoop版本演变历史
目前Hadoop经历了三个大的版本

从1.x到2.x再到3.x
每一个大版本的升级都带来了一些质的提升,下面我们先从架构层面分析一下这三大版本的变更:
hadoop1.x:HDFS+MapReduce
hadoop2.x:HDFS+YARN+MapReduce
hadoop3.x:HDFS+YARN+MapReduce

从Hadoop1.x升级到Hadoop2.x,架构发生了比较大的变化,这里面的HDFS是分布式存储,MapRecue是分布式计算,咱们前面说了Hadoop解决了分布式存储和分布式计算的问题,对应的就是这两个模块
在Hadoop2.x的架构中,多了一个模块 YARN,这个是一个负责资源管理的模块,那在Hadoop1.x中就不需要进行资源管理吗?
也是需要的,只不过是在Hadoop1.x中,分布式计算和资源管理都是MapReduce负责的,从Hadoop2.x开始把资源管理单独拆分出来了,拆分出来的好处就是,YARN变成了一个公共的资源管理平台,在它上面不仅仅可以跑MapReduce程序,还可以跑很多其他的程序,只要你的程序满足YARN的规则即可
Hadoop的这一步棋走的是最好的,这样自己摇身一变就变成了一个公共的平台,由于它起步早,占有的市场份额也多,后期其它新兴起的计算框架一般都会支持在YARN上面运行,这样Hadoop就保证了自己的地位。
咱们后面要学的Spark、Flink等计算框架都是支持在YARN上面执行的,并且在实际工作中也都是在YARN上面执行。
Hadoop3.x的架构并没有发生什么变化,但是它在其他细节方面做了很多优化
Hadoop3.x的细节优化
在这里我挑几个常见点说一下:
- 1:最低Java版本要求从Java7变为Java8
2:在Hadoop 3中,HDFS支持纠删码,纠删码是一种比副本存储更节省存储空间的数据持久化存储方法,使用这种方法,相同容错的情况下可以比之前节省一半的存储空间
详细介绍在这里: https://hadoop.apache.org/docs/r3.0.0/hadoop-project-dist/hadoop-hdfs/HDFSErasureCoding.html
3: Hadoop 2中的HDFS最多支持两个NameNode,一主一备,而Hadoop 3中的HDFS支持多个NameNode,一主多备
详细介绍在这里: https://hadoop.apache.org/docs/r3.0.0/hadoop-project-dist/hadoop-hdfs/HDFSErasureCoding.html
4:MapReduce任务级本地优化,MapReduce添加了映射输出收集器的本地化实现的支持。对于密集型的洗牌操作(shuffle-intensive)jobs,可以带来30%的性能提升,
详细介绍在这里: https://issues.apache.org/jira/browse/MAPREDUCE-2841
- 5:修改了多重服务的默认端口,Hadoop2中一些服务的端口和Hadoop3中是不一样的
总结: Hadoop 3和2之间的主要区别在于新版本提供了更好的优化和可用性
详细的优化点也可以参考官网内容: https://hadoop.apache.org/docs/r3.0.0/index.html
Hadoop三大核心组件介绍
接下来我们就来介绍一下Hadoop中的三大核心组件,在这里Hadoop其实就是一个统称,它里面包含了多个功能模块
Hadoop主要包含三大组件:HDFS+MapReduce+YARN
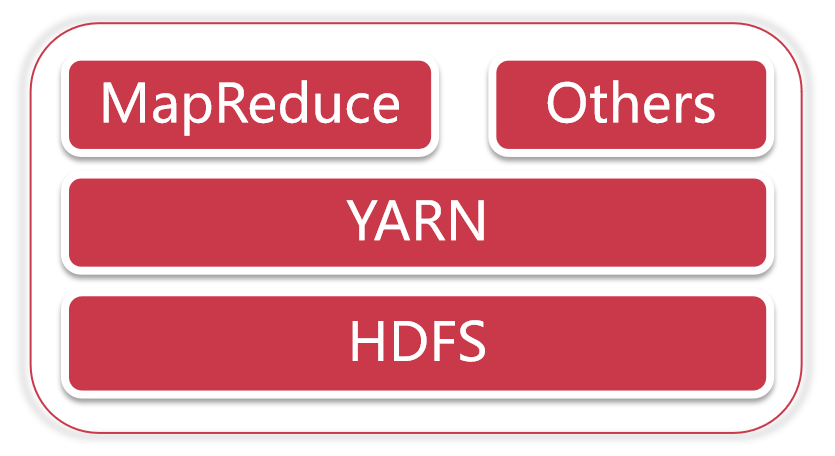
- HDFS负责海量数据的分布式存储
- MapReduce是一个计算模型,负责海量数据的分布式计算
- YARN主要负责集群资源的管理和调度