HDFS的高可用和高扩展
针对目前这个一主两从的集群
我们前面分析了NameNode负责接收用户的操作请求,所有的读写请求都会经过它,如果它挂了怎么办?
这个时候集群是不是就无法正常提供服务了?是的,那现在我们这个集群就太不稳定了,因为NameNode只有一个,是存在单点故障的,咱们在现实生活中,例如,县长,是有正的和副的,这样就是为了解决当正县长遇到出差的时候,副县长可以顶上去。
所以在HDFS的设计中,NameNode也是可以支持多个的,一个主的 多个备用的,,当主的挂掉了,备用的可以顶上去,这样就可以解决NameNode节点宕机导致的单点故障问题了,也就实现了HDFS的高可用
还有一个问题是,前面我们说了NameNode节点的内存是有限的,只能存储有限的文件个数,那使用一个主NameNode,多个备用的NameNode能解决这个问题吗?
不能!
一个主NameNode,多个备用的NameNode的方案只能解决NameNode的单点故障问题,无法解决单个NameNode内存不够用的问题,那怎么办呢?不用担心,官方提供了Federation机制,可以翻译为联邦,它可以解决单节点内存不够用的情况,具体实现思路我们稍后分析,这个就是HDFS的高扩展
目录
HDFS的高可用(HA)
下面我们首先来看一下HDFS的高可用,也可以称之为HA(High Available)
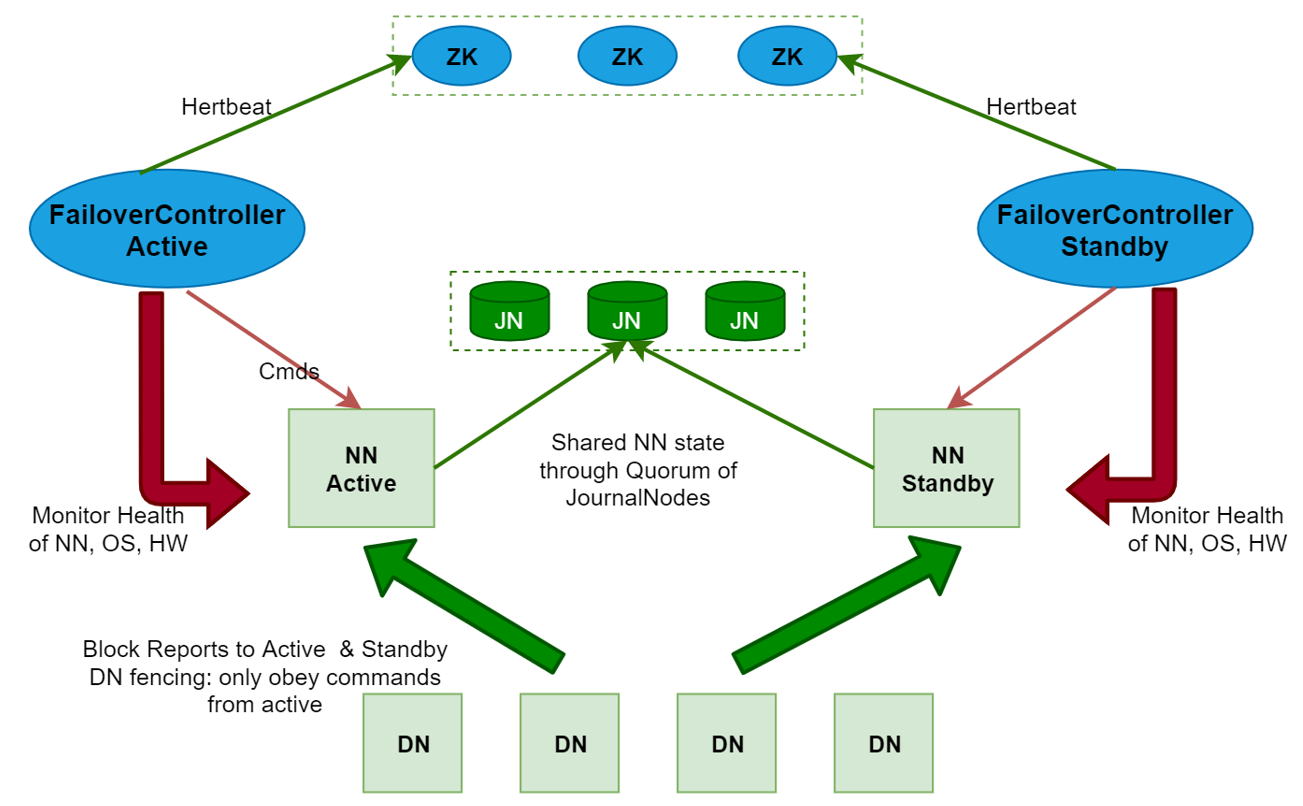
HDFS的HA,指的是在一个集群中存在多个NameNode,分别运行在独立的物理节点上。在任何时间点,只有一个NameNode是处于Active状态,其它的是处于Standby状态。 Active NameNode(简写为Active NN)负责所有的客户端的操作,而Standby NameNode(简写为Standby NN)用来同步Active NameNode的状态信息,以提供快速的故障恢复能力。
为了保证Active NN与Standby NN节点状态同步,即元数据保持一致。除了DataNode需要向这些NameNode发送block位置信息外,还构建了一组独立的守护进程”JournalNodes”(简写为JN),用来同步Edits信息。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JNs上。而Standby NN负责观察JNs的变化,读取从Active NN发送过来的Edits信息,并更新自己内部的命名空间。一旦Active NN遇到错误,Standby NN需要保证从JNs中读出了全部的Edits,然后切换成Active状态,如果有多个Standby NN,还会涉及到选主的操作,选择一个切换为Active 状态。
需要注意一点,为了保证Active NN与Standby NN节点状态同步,即元数据保持一致
这里的元数据包含两块,一个是静态的,一个是动态的
静态的是fsimage和edits,其实fsimage是由edits文件合并生成的,所以只需要保证edits文件内容的一致性。这个就是需要保证多个NameNode中edits文件内容的事务性同步。这块的工作是由JournalNodes集群进行同步的
动态数据是指block和DataNode节点的信息,这个如何保证呢? 当DataNode启动的时候,上报数据信息的时候需要向每个NameNode都上报一份。 这样就可以保证多个NameNode的元数据信息都一样了,当一个NameNode down掉以后,立刻从Standby NN中选择一个进行接管,没有影响,因为每个NameNode 的元数据时刻都是同步的。
注意:使用HA的时候,不能启动SecondaryNameNode,会出错。 之前是SecondaryNameNode负责合并edits到fsimage文件 那么现在这个工作被standby NN负责了。
NameNode 切换可以自动切换,也可以手工切换,如果想要实现自动切换,需要使用到zookeeper集群。
使用zookeeper集群自动切换的原理是这样的
当多个NameNode 启动的时候会向zookeeper中注册一个临时节点,当NameNode挂掉的时候,这个临时节点也就消失了,这属于zookeeper的特性,这个时候,zookeeper就会有一个watcher监视器监视到,就知道这个节点down掉了,然后会选择一个节点转为Active,把down掉的节点转为Standby。
HDFS的高扩展(Federation)
HDFS Federation可以解决单一命名空间存在的问题,使用多个NameNode,每个NameNode负责一个命令空间
这种设计可提供以下特性:
1:HDFS集群扩展性。多个NameNode分管一部分目录,使得一个集群可以扩展到更多节点,不再因内存的限制制约文件存储数目。
2:性能更高效。多个NameNode管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率。
3:良好的隔离性。用户可根据需要将不同业务数据交由不同NameNode管理,这样不同业务之间影响很小。
如果真用到了Federation,一般也会和前面我们讲的HA结合起来使用,来看这个图
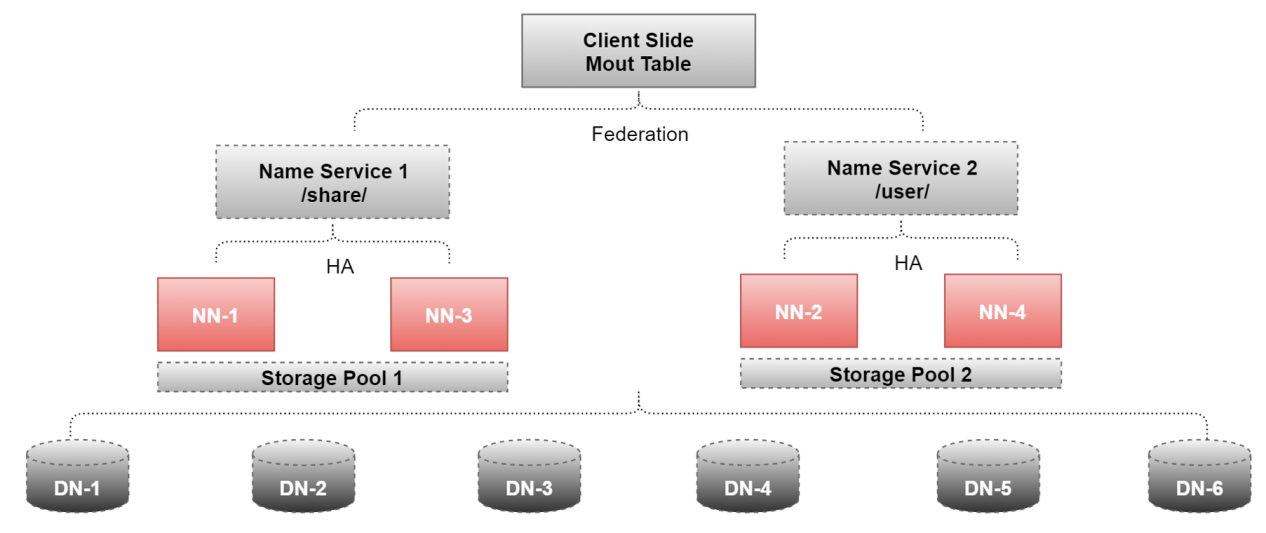
这里面用到了4个NameNode和6个DataNode
NN-1、NN-2、NN-3、NN-4
DN-1、DN-2、DN-3、DN-4、DN-5、DN-6、
其中NN-1、和NN-3配置了HA,提供了一个命令空间,/share,其实可理解为一个顶级目录
NN-2和NN-4配置了HA,提供了一个命名空间,/user
这样后期我们存储数据的时候,就可以根据数据的业务类型来区分是存储到share目录下还是user目录下,此时HDFS的存储能力就是/share和/user两个命名空间的总和了。